 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetaFormer-driven Encoding Network for Robust Medical Semantic Segmentation
Jan 01, 2026Semantic segmentation is crucial for medical image analysis, enabling precise disease diagnosis and treatment planning. However, many advanced models employ complex architectures, limiting their use in resource-constrained clinical settings. This paper proposes MFEnNet, an efficient medical image segmentation framework that incorporates MetaFormer in the encoding phase of the U-Net backbone. MetaFormer, an architectural abstraction of vision transformers, provides a versatile alternative to convolutional neural networks by transforming tokenized image patches into sequences for global context modeling. To mitigate the substantial computational cost associated with self-attention, the proposed framework replaces conventional transformer modules with pooling transformer blocks, thereby achieving effective global feature aggregation at reduced complexity. In addition, Swish activation is used to achieve smoother gradients and faster convergence, while spatial pyramid pooling is incorporated at the bottleneck to improve multi-scale feature extraction. Comprehensive experiments on different medical segmentation benchmarks demonstrate that the proposed MFEnNet approach attains competitive accuracy while significantly lowering computational cost compared to state-of-the-art models. The source code for this work is available at https://github.com/tranleanh/mfennet.
BronchoPose: an analysis of data and model configuration for vision-based bronchoscopy pose estimation
Apr 25, 2022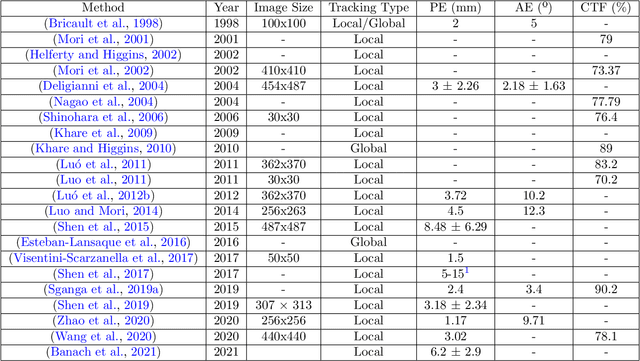
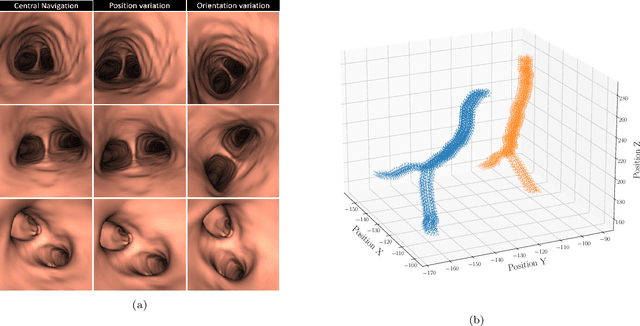
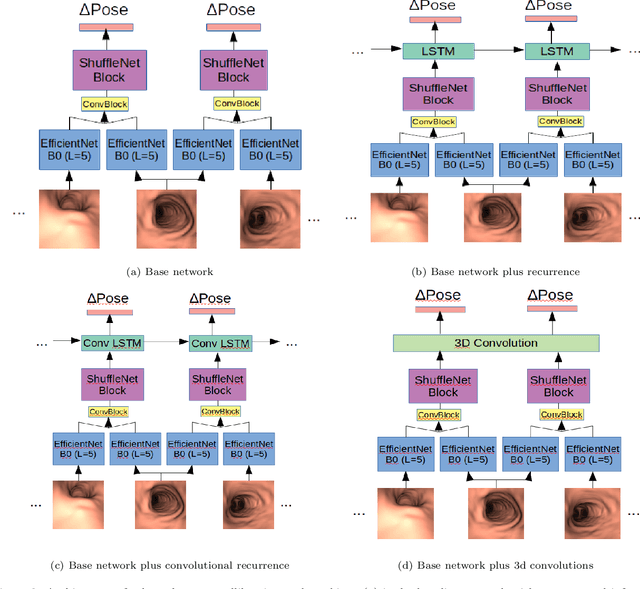
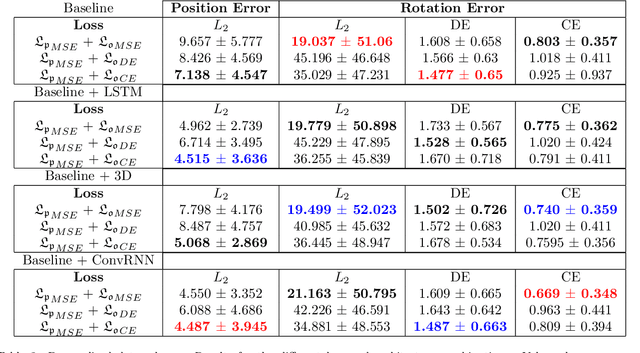
Vision-based bronchoscopy (VB) models require the registration of the virtual lung model with the frames from the video bronchoscopy to provide effective guidance during the biopsy. The registration can be achieved by either tracking the position and orientation of the bronchoscopy camera or by calibrating its deviation from the pose (position and orientation) simulated in the virtual lung model. Recent advances in neural networks and temporal image processing have provided new opportunities for guided bronchoscopy. However, such progress has been hindered by the lack of comparative experimental conditions. In the present paper, we share a novel synthetic dataset allowing for a fair comparison of methods. Moreover, this paper investigates several neural network architectures for the learning of temporal information at different levels of subject personalization. In order to improve orientation measurement, we also present a standardized comparison framework and a novel metric for camera orientation learning. Results on the dataset show that the proposed metric and architectures, as well as the standardized conditions, provide notable improvements to current state-of-the-art camera pose estimation in video bronchoscopy.
OpenCL-based FPGA accelerator for disparity map generation with stereoscopic event cameras
Mar 08, 2019
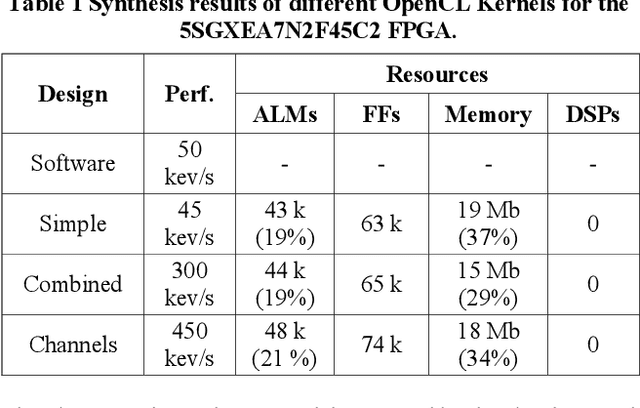

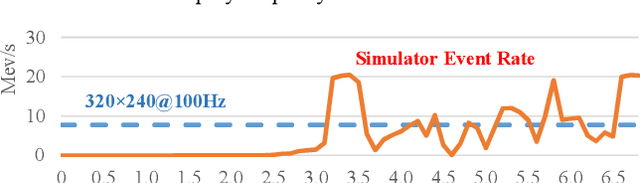
Although event-based cameras are already commercially available. Vision algorithms based on them are still not common. As a consequence, there are few Hardware Accelerators for them. In this work we present some experiments to create FPGA accelerators for a well-known vision algorithm using event-based cameras. We present a stereo matching algorithm to create a stream of disparity events disparity map and implement several accelerators using the Intel FPGA OpenCL tool-chain. The results show that multiple designs can be easily tested and that a performance speedup of more than 8x can be achieved with simple code transformations.
A High-Performance HOG Extractor on FPGA
Jan 12, 2018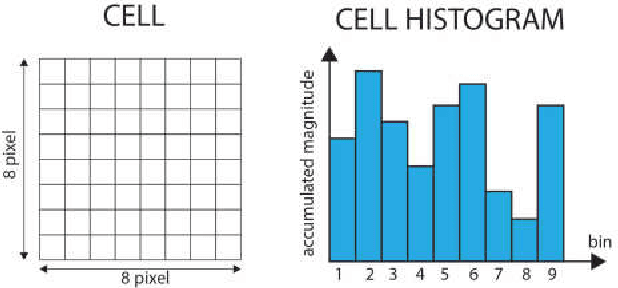
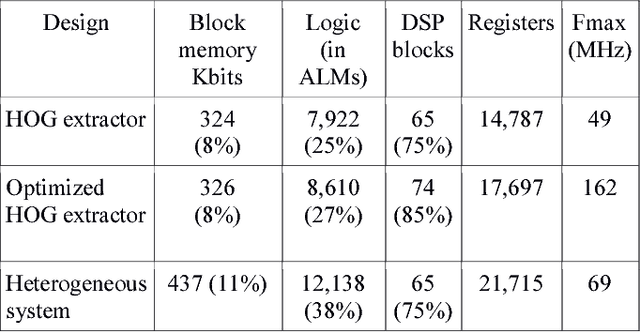
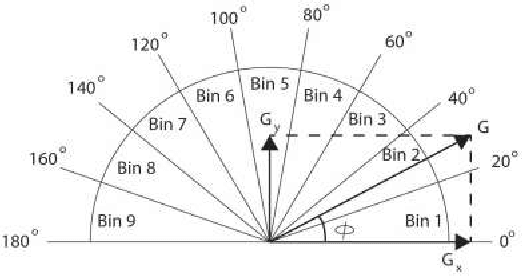
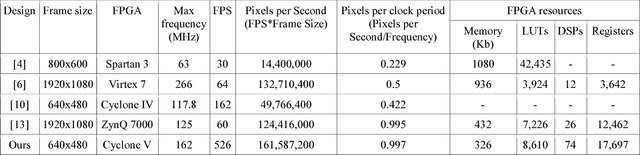
Pedestrian detection is one of the key problems in emerging self-driving car industry. And HOG algorithm has proven to provide good accuracy for pedestrian detection. There are plenty of research works have been done in accelerating HOG algorithm on FPGA because of its low-power and high-throughput characteristics. In this paper, we present a high-performance HOG architecture for pedestrian detection on a low-cost FPGA platform. It achieves a maximum throughput of 526 FPS with 640x480 input images, which is 3.25 times faster than the state of the art design. The accelerator is integrated with SVM-based prediction in realizing a pedestrian detection system. And the power consumption of the whole system is comparable with the best existing implementations.