 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLinking Geographic Vocabularies through WordNet
Apr 22, 2014



The linked open data (LOD) paradigm has emerged as a promising approach to structuring and sharing geospatial information. One of the major obstacles to this vision lies in the difficulties found in the automatic integration between heterogeneous vocabularies and ontologies that provides the semantic backbone of the growing constellation of open geo-knowledge bases. In this article, we show how to utilize WordNet as a semantic hub to increase the integration of LOD. With this purpose in mind, we devise Voc2WordNet, an unsupervised mapping technique between a given vocabulary and WordNet, combining intensional and extensional aspects of the geographic terms. Voc2WordNet is evaluated against a sample of human-generated alignments with the OpenStreetMap (OSM) Semantic Network, a crowdsourced geospatial resource, and the GeoNames ontology, the vocabulary of a large digital gazetteer. These empirical results indicate that the approach can obtain high precision and recall.
* 21 pages, 1 figure
An evaluative baseline for geo-semantic relatedness and similarity
Feb 14, 2014
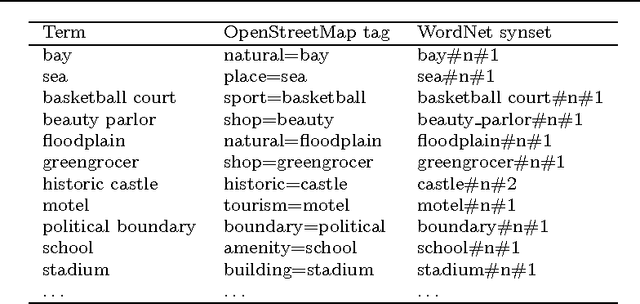
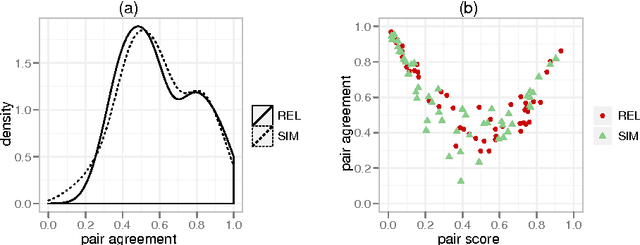
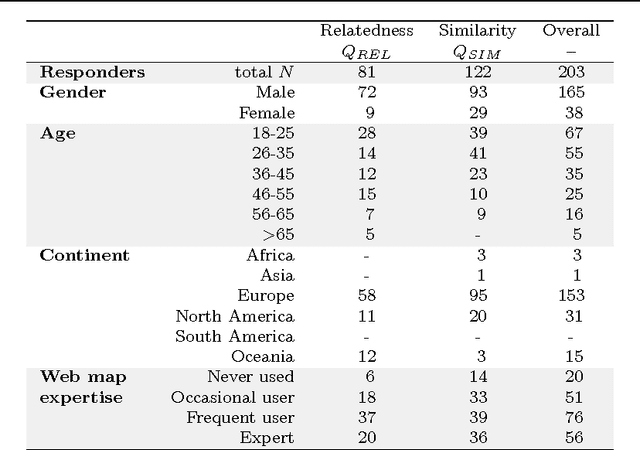
In geographic information science and semantics, the computation of semantic similarity is widely recognised as key to supporting a vast number of tasks in information integration and retrieval. By contrast, the role of geo-semantic relatedness has been largely ignored. In natural language processing, semantic relatedness is often confused with the more specific semantic similarity. In this article, we discuss a notion of geo-semantic relatedness based on Lehrer's semantic fields, and we compare it with geo-semantic similarity. We then describe and validate the Geo Relatedness and Similarity Dataset (GeReSiD), a new open dataset designed to evaluate computational measures of geo-semantic relatedness and similarity. This dataset is larger than existing datasets of this kind, and includes 97 geographic terms combined into 50 term pairs rated by 203 human subjects. GeReSiD is available online and can be used as an evaluation baseline to determine empirically to what degree a given computational model approximates geo-semantic relatedness and similarity.
The semantic similarity ensemble
Jan 11, 2014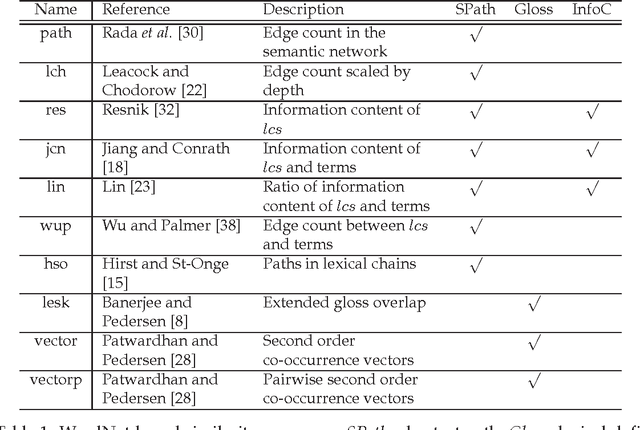



Computational measures of semantic similarity between geographic terms provide valuable support across geographic information retrieval, data mining, and information integration. To date, a wide variety of approaches to geo-semantic similarity have been devised. A judgment of similarity is not intrinsically right or wrong, but obtains a certain degree of cognitive plausibility, depending on how closely it mimics human behavior. Thus selecting the most appropriate measure for a specific task is a significant challenge. To address this issue, we make an analogy between computational similarity measures and soliciting domain expert opinions, which incorporate a subjective set of beliefs, perceptions, hypotheses, and epistemic biases. Following this analogy, we define the semantic similarity ensemble (SSE) as a composition of different similarity measures, acting as a panel of experts having to reach a decision on the semantic similarity of a set of geographic terms. The approach is evaluated in comparison to human judgments, and results indicate that an SSE performs better than the average of its parts. Although the best member tends to outperform the ensemble, all ensembles outperform the average performance of each ensemble's member. Hence, in contexts where the best measure is unknown, the ensemble provides a more cognitively plausible approach.
* Special feature on Semantic and Conceptual Issues in GIS (SeCoGIS)