 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn evaluative baseline for geo-semantic relatedness and similarity
Paper and Code

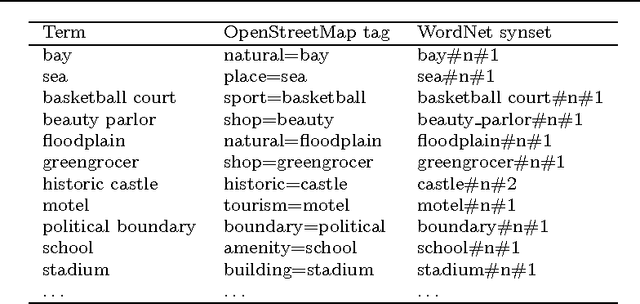
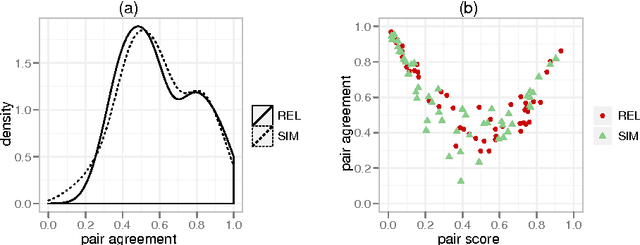
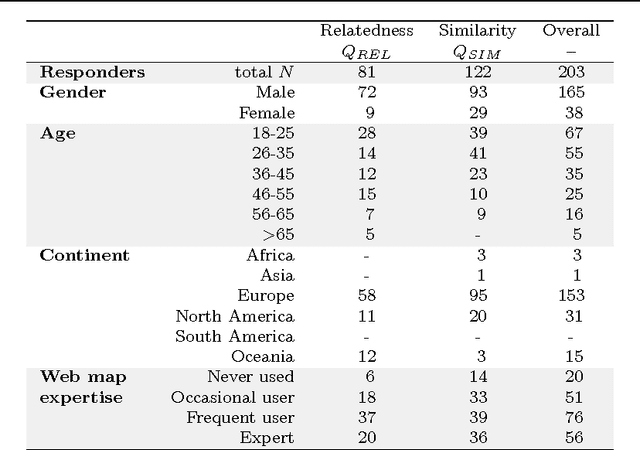
In geographic information science and semantics, the computation of semantic similarity is widely recognised as key to supporting a vast number of tasks in information integration and retrieval. By contrast, the role of geo-semantic relatedness has been largely ignored. In natural language processing, semantic relatedness is often confused with the more specific semantic similarity. In this article, we discuss a notion of geo-semantic relatedness based on Lehrer's semantic fields, and we compare it with geo-semantic similarity. We then describe and validate the Geo Relatedness and Similarity Dataset (GeReSiD), a new open dataset designed to evaluate computational measures of geo-semantic relatedness and similarity. This dataset is larger than existing datasets of this kind, and includes 97 geographic terms combined into 50 term pairs rated by 203 human subjects. GeReSiD is available online and can be used as an evaluation baseline to determine empirically to what degree a given computational model approximates geo-semantic relatedness and similarity.