 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCrowdsourcing Relative Rankings of Multi-Word Expressions: Experts versus Non-Experts
Jun 17, 2022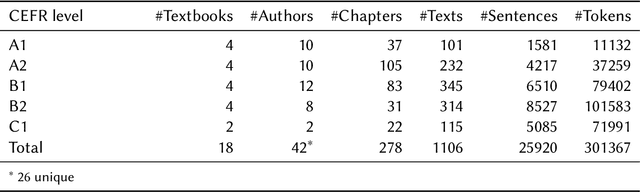
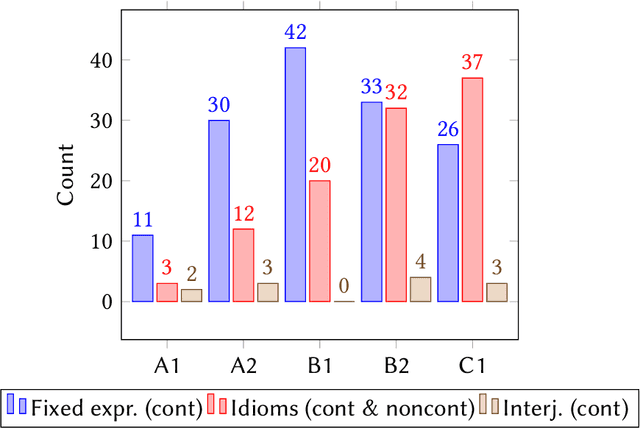
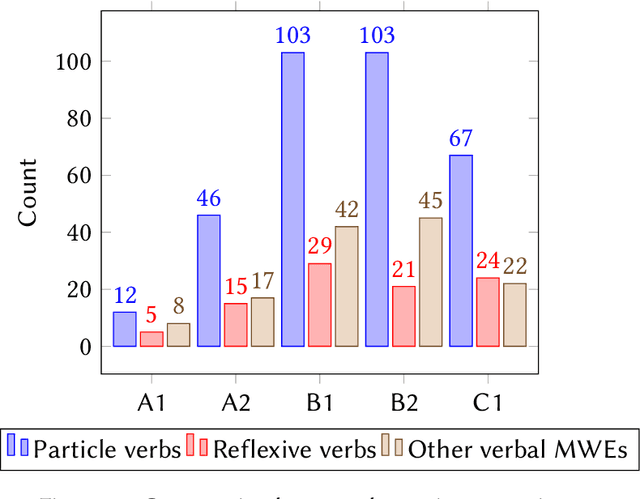
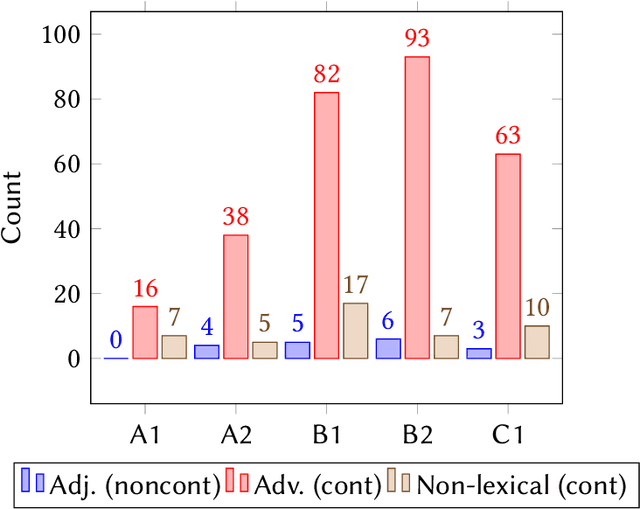
In this study we investigate to which degree experts and non-experts agree on questions of difficulty in a crowdsourcing experiment. We ask non-experts (second language learners of Swedish) and two groups of experts (teachers of Swedish as a second/foreign language and CEFR experts) to rank multi-word expressions in a crowdsourcing experiment. We find that the resulting rankings by all the three tested groups correlate to a very high degree, which suggests that judgments produced in a comparative setting are not influenced by professional insights into Swedish as a second language.
An exploratory study of L1-specific non-words
Sep 02, 2020



In this paper, we explore L1-specific non-words, i.e. non-words in a target language (in this case Swedish) that are re-ranked by a different-language language model. We surmise that speakers of a certain L1 will react different to L1-specific non-words than to general non-words. We present the results from two small case studies exploring whether re-ranking non-words with different language models leads to a perceived difference in `Swedishness' (pilot study 1) and whether German and English native speakers have longer reaction times in a lexical decision task when presented with their respective L1-specific non-words (pilot study 2). Tentative results seem to indicate that L1-specific non-words are processed second-slowest, after purely Swedish-looking non-words.
Language Segmentation
Oct 06, 2015



Language segmentation consists in finding the boundaries where one language ends and another language begins in a text written in more than one language. This is important for all natural language processing tasks. The problem can be solved by training language models on language data. However, in the case of low- or no-resource languages, this is problematic. I therefore investigate whether unsupervised methods perform better than supervised methods when it is difficult or impossible to train supervised approaches. A special focus is given to difficult texts, i.e. texts that are rather short (one sentence), containing abbreviations, low-resource languages and non-standard language. I compare three approaches: supervised n-gram language models, unsupervised clustering and weakly supervised n-gram language model induction. I devised the weakly supervised approach in order to deal with difficult text specifically. In order to test the approach, I compiled a small corpus of different text types, ranging from one-sentence texts to texts of about 300 words. The weakly supervised language model induction approach works well on short and difficult texts, outperforming the clustering algorithm and reaching scores in the vicinity of the supervised approach. The results look promising, but there is room for improvement and a more thorough investigation should be undertaken.
Analyzer and generator for Pali
Oct 06, 2015This work describes a system that performs morphological analysis and generation of Pali words. The system works with regular inflectional paradigms and a lexical database. The generator is used to build a collection of inflected and derived words, which in turn is used by the analyzer. Generating and storing morphological forms along with the corresponding morphological information allows for efficient and simple look up by the analyzer. Indeed, by looking up a word and extracting the attached morphological information, the analyzer does not have to compute this information. As we must, however, assume the lexical database to be incomplete, the system can also work without the dictionary component, using a rule-based approach.