 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End Information Extraction by Character-Level Embedding and Multi-Stage Attentional U-Net
Jun 02, 2021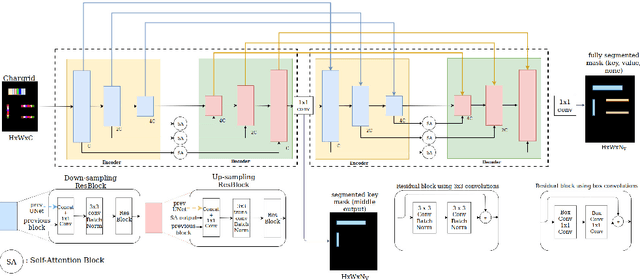

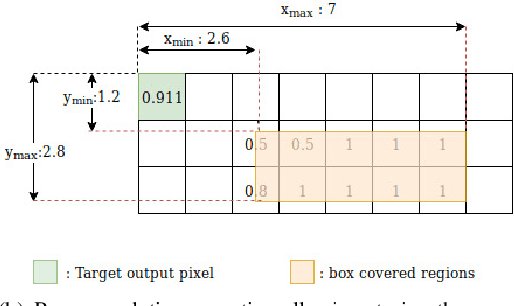
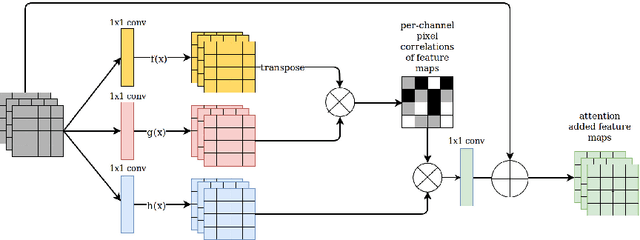
Information extraction from document images has received a lot of attention recently, due to the need for digitizing a large volume of unstructured documents such as invoices, receipts, bank transfers, etc. In this paper, we propose a novel deep learning architecture for end-to-end information extraction on the 2D character-grid embedding of the document, namely the \textit{Multi-Stage Attentional U-Net}. To effectively capture the textual and spatial relations between 2D elements, our model leverages a specialized multi-stage encoder-decoders design, in conjunction with efficient uses of the self-attention mechanism and the box convolution. Experimental results on different datasets show that our model outperforms the baseline U-Net architecture by a large margin while using 40\% fewer parameters. Moreover, it also significantly improved the baseline in erroneous OCR and limited training data scenario, thus becomes practical for real-world applications.
* Accepted to BMVC 2019