 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDocument Image Coding and Clustering for Script Discrimination
Sep 21, 2016
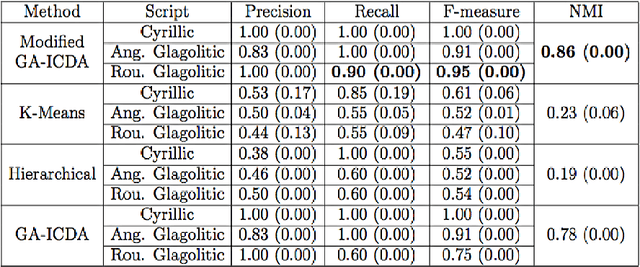

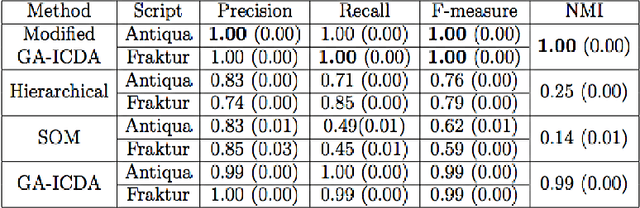
The paper introduces a new method for discrimination of documents given in different scripts. The document is mapped into a uniformly coded text of numerical values. It is derived from the position of the letters in the text line, based on their typographical characteristics. Each code is considered as a gray level. Accordingly, the coded text determines a 1-D image, on which texture analysis by run-length statistics and local binary pattern is performed. It defines feature vectors representing the script content of the document. A modified clustering approach employed on document feature vector groups documents written in the same script. Experimentation performed on two custom oriented databases of historical documents in old Cyrillic, angular and round Glagolitic as well as Antiqua and Fraktur scripts demonstrates the superiority of the proposed method with respect to well-known methods in the state-of-the-art.
* 8 pages, 4 figures, 2 tables
An Approach to the Analysis of the South Slavic Medieval Labels Using Image Texture
Sep 07, 2015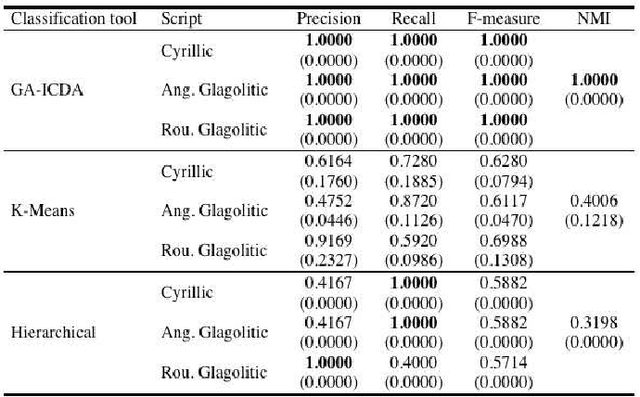
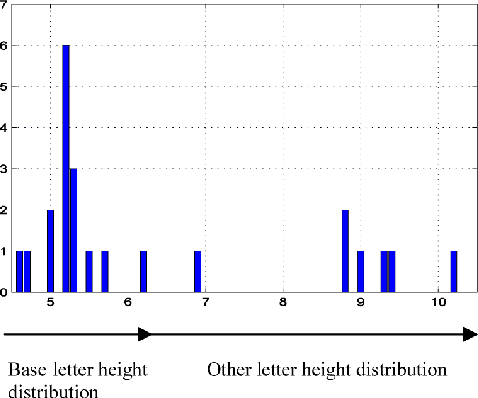
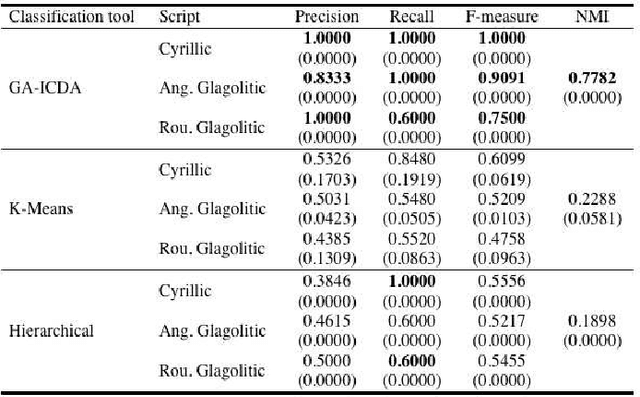

The paper presents a new script classification method for the discrimination of the South Slavic medieval labels. It consists in the textural analysis of the script types. In the first step, each letter is coded by the equivalent script type, which is defined by its typographical features. Obtained coded text is subjected to the run-length statistical analysis and to the adjacent local binary pattern analysis in order to extract the features. The result shows a diversity between the extracted features of the scripts, which makes the feature classification more effective. It is the basis for the classification process of the script identification by using an extension of a state-of-the-art approach for document clustering. The proposed method is evaluated on an example of hand-engraved in stone and hand-printed in paper labels in old Cyrillic, angular and round Glagolitic. Experiments demonstrate very positive results, which prove the effectiveness of the proposed method.
Analysis of the South Slavic Scripts by Run-Length Features of the Image Texture
Jul 17, 2015

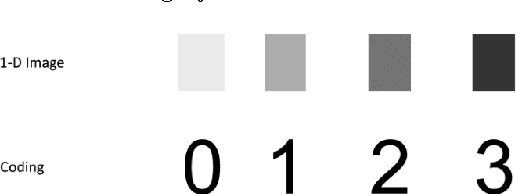
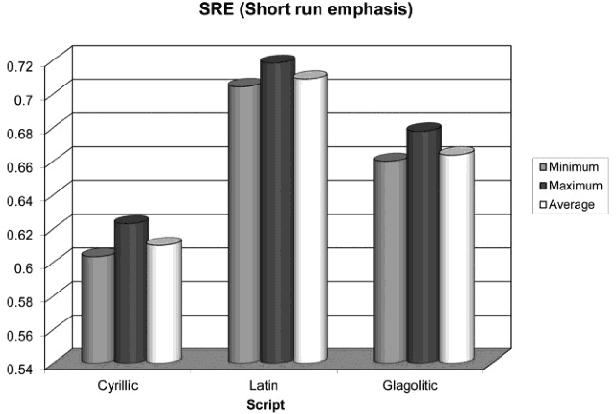
The paper proposes an algorithm for the script recognition based on the texture characteristics. The image texture is achieved by coding each letter with the equivalent script type (number code) according to its position in the text line. Each code is transformed into equivalent gray level pixel creating an 1-D image. Then, the image texture is subjected to the run-length analysis. This analysis extracts the run-length features, which are classified to make a distinction between the scripts under consideration. In the experiment, a custom oriented database is subject to the proposed algorithm. The database consists of some text documents written in Cyrillic, Latin and Glagolitic scripts. Furthermore, it is divided into training and test parts. The results of the experiment show that 3 out of 5 run-length features can be used for effective differentiation between the analyzed South Slavic scripts.
* 9 pages, 9 figures, In Electronics 2015, Elektronika IR Elektrotechnika, ISSN 1392-1215 (in press)