 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLying Graph Convolution: Learning to Lie for Node Classification Tasks
May 02, 2024In the context of machine learning for graphs, many researchers have empirically observed that Deep Graph Networks (DGNs) perform favourably on node classification tasks when the graph structure is homophilic (\ie adjacent nodes are similar). In this paper, we introduce Lying-GCN, a new DGN inspired by opinion dynamics that can adaptively work in both the heterophilic and the homophilic setting. At each layer, each agent (node) shares its own opinions (node embeddings) with its neighbours. Instead of sharing its opinion directly as in GCN, we introduce a mechanism which allows agents to lie. Such a mechanism is adaptive, thus the agents learn how and when to lie according to the task that should be solved. We provide a characterisation of our proposal in terms of dynamical systems, by studying the spectral property of the coefficient matrix of the system. While the steady state of the system collapses to zero, we believe the lying mechanism is still usable to solve node classification tasks. We empirically prove our belief on both synthetic and real-world datasets, by showing that the lying mechanism allows to increase the performances in the heterophilic setting without harming the results in the homophilic one.
Investigating the Interplay between Features and Structures in Graph Learning
Aug 18, 2023In the past, the dichotomy between homophily and heterophily has inspired research contributions toward a better understanding of Deep Graph Networks' inductive bias. In particular, it was believed that homophily strongly correlates with better node classification predictions of message-passing methods. More recently, however, researchers pointed out that such dichotomy is too simplistic as we can construct node classification tasks where graphs are completely heterophilic but the performances remain high. Most of these works have also proposed new quantitative metrics to understand when a graph structure is useful, which implicitly or explicitly assume the correlation between node features and target labels. Our work empirically investigates what happens when this strong assumption does not hold, by formalising two generative processes for node classification tasks that allow us to build and study ad-hoc problems. To quantitatively measure the influence of the node features on the target labels, we also use a metric we call Feature Informativeness. We construct six synthetic tasks and evaluate the performance of six models, including structure-agnostic ones. Our findings reveal that previously defined metrics are not adequate when we relax the above assumption. Our contribution to the workshop aims at presenting novel research findings that could help advance our understanding of the field.
Learning from Non-Binary Constituency Trees via Tensor Decomposition
Nov 02, 2020



Processing sentence constituency trees in binarised form is a common and popular approach in literature. However, constituency trees are non-binary by nature. The binarisation procedure changes deeply the structure, furthering constituents that instead are close. In this work, we introduce a new approach to deal with non-binary constituency trees which leverages tensor-based models. In particular, we show how a powerful composition function based on the canonical tensor decomposition can exploit such a rich structure. A key point of our approach is the weight sharing constraint imposed on the factor matrices, which allows limiting the number of model parameters. Finally, we introduce a Tree-LSTM model which takes advantage of this composition function and we experimentally assess its performance on different NLP tasks.
Tensor Decompositions in Recursive NeuralNetworks for Tree-Structured Data
Jun 18, 2020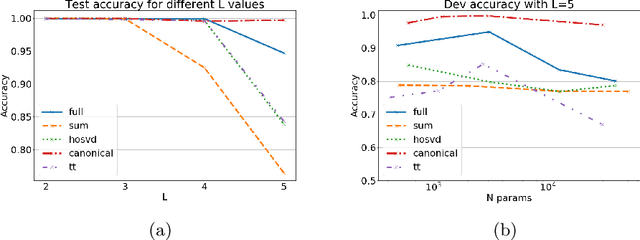

The paper introduces two new aggregation functions to encode structural knowledge from tree-structured data. They leverage the Canonical and Tensor-Train decompositions to yield expressive context aggregation while limiting the number of model parameters. Finally, we define two novel neural recursive models for trees leveraging such aggregation functions, and we test them on two tree classification tasks, showing the advantage of proposed models when tree outdegree increases.
Generalising Recursive Neural Models by Tensor Decomposition
Jun 17, 2020



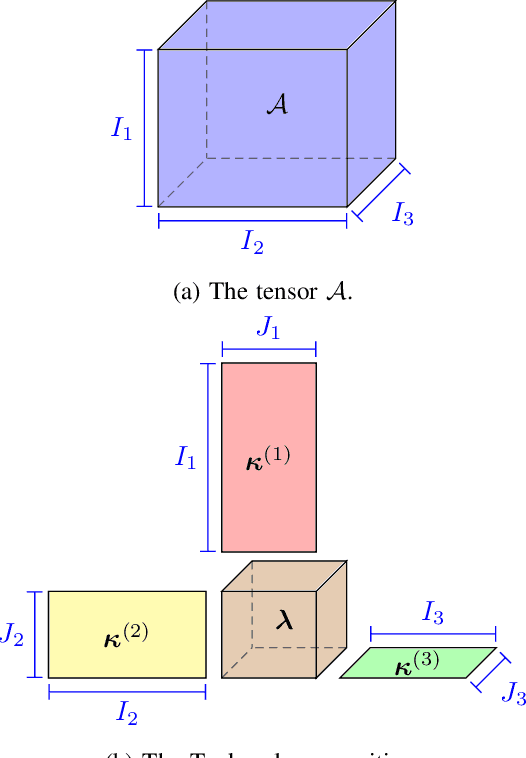
Most machine learning models for structured data encode the structural knowledge of a node by leveraging simple aggregation functions (in neural models, typically a weighted sum) of the information in the node's neighbourhood. Nevertheless, the choice of simple context aggregation functions, such as the sum, can be widely sub-optimal. In this work we introduce a general approach to model aggregation of structural context leveraging a tensor-based formulation. We show how the exponential growth in the size of the parameter space can be controlled through an approximation based on the Tucker tensor decomposition. This approximation allows limiting the parameters space size, decoupling it from its strict relation with the size of the hidden encoding space. By this means, we can effectively regulate the trade-off between expressivity of the encoding, controlled by the hidden size, computational complexity and model generalisation, influenced by parameterisation. Finally, we introduce a new Tensorial Tree-LSTM derived as an instance of our framework and we use it to experimentally assess our working hypotheses on tree classification scenarios.
Bayesian Tensor Factorisation for Bottom-up Hidden Tree Markov Models
May 31, 2019
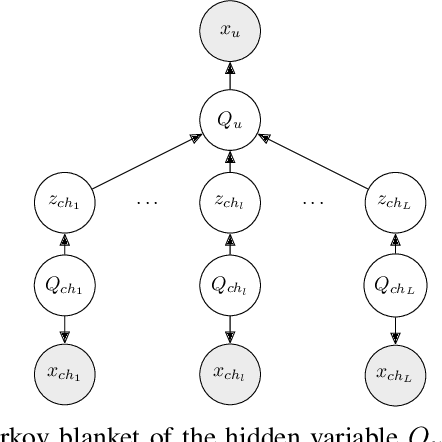

Bottom-Up Hidden Tree Markov Model is a highly expressive model for tree-structured data. Unfortunately, it cannot be used in practice due to the intractable size of its state-transition matrix. We propose a new approximation which lies on the Tucker factorisation of tensors. The probabilistic interpretation of such approximation allows us to define a new probabilistic model for tree-structured data. Hence, we define the new approximated model and we derive its learning algorithm. Then, we empirically assess the effective power of the new model evaluating it on two different tasks. In both cases, our model outperforms the other approximated model known in the literature.
Learning Tree Distributions by Hidden Markov Models
May 31, 2018

Hidden tree Markov models allow learning distributions for tree structured data while being interpretable as nondeterministic automata. We provide a concise summary of the main approaches in literature, focusing in particular on the causality assumptions introduced by the choice of a specific tree visit direction. We will then sketch a novel non-parametric generalization of the bottom-up hidden tree Markov model with its interpretation as a nondeterministic tree automaton with infinite states.