 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompNet: A Designated Model to Handle Combinations of Images and Designed features
Sep 28, 2022
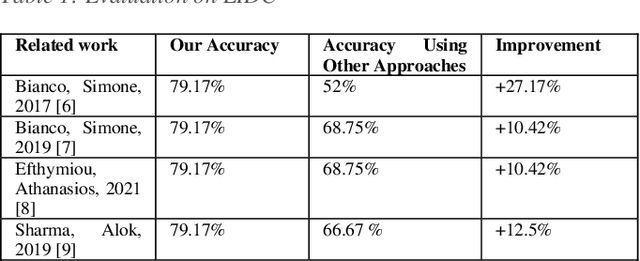

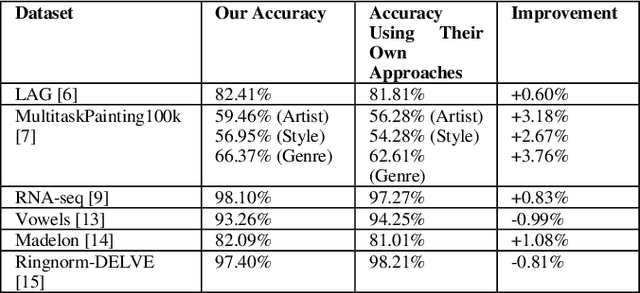
Convolutional neural networks (CNNs) are one of the most popular models of Artificial Neural Networks (ANN)s in Computer Vision (CV). A variety of CNN-based structures were developed by researchers to solve problems like image classification, object detection, and image similarity measurement. Although CNNs have shown their value in most cases, they still have a downside: they easily overfit when there are not enough samples in the dataset. Most medical image datasets are examples of such a dataset. Additionally, many datasets also contain both designed features and images, but CNNs can only deal with images directly. This represents a missed opportunity to leverage additional information. For this reason, we propose a new structure of CNN-based model: CompNet, a composite convolutional neural network. This is a specially designed neural network that accepts combinations of images and designed features as input in order to leverage all available information. The novelty of this structure is that it uses learned features from images to weight designed features in order to gain all information from both images and designed features. With the use of this structure on classification tasks, the results indicate that our approach has the capability to significantly reduce overfitting. Furthermore, we also found several similar approaches proposed by other researchers that can combine images and designed features. To make comparison, we first applied those similar approaches on LIDC and compared the results with the CompNet results, then we applied our CompNet on the datasets that those similar approaches originally used in their works and compared the results with the results they proposed in their papers. All these comparison results showed that our model outperformed those similar approaches on classification tasks either on LIDC dataset or on their proposed datasets.
Visual Explanations from Deep Networks via Riemann-Stieltjes Integrated Gradient-based Localization
May 22, 2022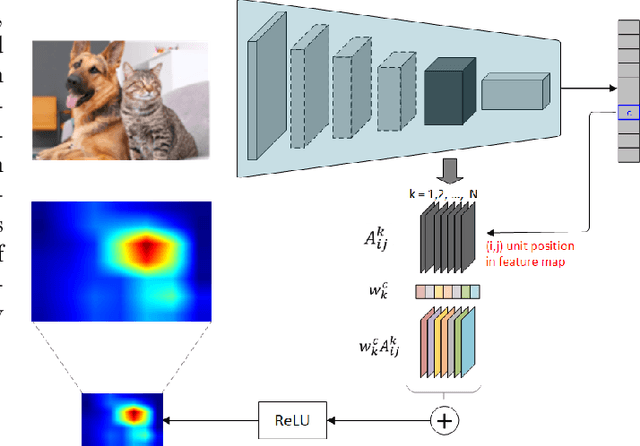

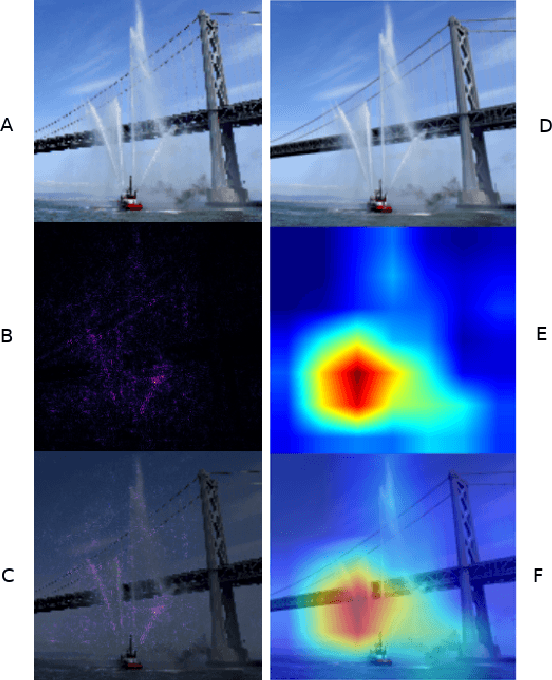
Neural networks are becoming increasingly better at tasks that involve classifying and recognizing images. At the same time techniques intended to explain the network output have been proposed. One such technique is the Gradient-based Class Activation Map (Grad-CAM), which is able to locate features of an input image at various levels of a convolutional neural network (CNN), but is sensitive to the vanishing gradients problem. There are techniques such as Integrated Gradients (IG), that are not affected by that problem, but its use is limited to the input layer of a network. Here we introduce a new technique to produce visual explanations for the predictions of a CNN. Like Grad-CAM, our method can be applied to any layer of the network, and like Integrated Gradients it is not affected by the problem of vanishing gradients. For efficiency, gradient integration is performed numerically at the layer level using a Riemann-Stieltjes sum approximation. Compared to Grad-CAM, heatmaps produced by our algorithm are better focused in the areas of interest, and their numerical computation is more stable. Our code is available at https://github.com/mlerma54/RSIGradCAM