 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigation of reinforcement learning for shape optimization of profile extrusion dies
Dec 23, 2022



Profile extrusion is a continuous production process for manufacturing plastic profiles from molten polymer. Especially interesting is the design of the die, through which the melt is pressed to attain the desired shape. However, due to an inhomogeneous velocity distribution at the die exit or residual stresses inside the extrudate, the final shape of the manufactured part often deviates from the desired one. To avoid these deviations, the shape of the die can be computationally optimized, which has already been investigated in the literature using classical optimization approaches. A new approach in the field of shape optimization is the utilization of Reinforcement Learning (RL) as a learning-based optimization algorithm. RL is based on trial-and-error interactions of an agent with an environment. For each action, the agent is rewarded and informed about the subsequent state of the environment. While not necessarily superior to classical, e.g., gradient-based or evolutionary, optimization algorithms for one single problem, RL techniques are expected to perform especially well when similar optimization tasks are repeated since the agent learns a more general strategy for generating optimal shapes instead of concentrating on just one single problem. In this work, we investigate this approach by applying it to two 2D test cases. The flow-channel geometry can be modified by the RL agent using so-called Free-Form Deformation, a method where the computational mesh is embedded into a transformation spline, which is then manipulated based on the control-point positions. In particular, we investigate the impact of utilizing different agents on the training progress and the potential of wall time saving by utilizing multiple environments during training.
A Convolutional-Attentional Neural Framework for Structure-Aware Performance-Score Synchronization
Apr 19, 2022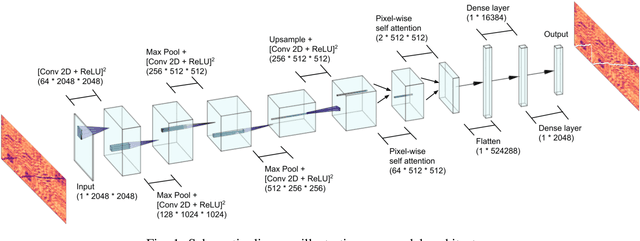

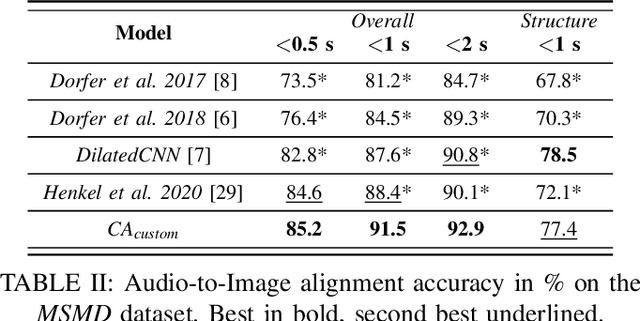
Performance-score synchronization is an integral task in signal processing, which entails generating an accurate mapping between an audio recording of a performance and the corresponding musical score. Traditional synchronization methods compute alignment using knowledge-driven and stochastic approaches, and are typically unable to generalize well to different domains and modalities. We present a novel data-driven method for structure-aware performance-score synchronization. We propose a convolutional-attentional architecture trained with a custom loss based on time-series divergence. We conduct experiments for the audio-to-MIDI and audio-to-image alignment tasks pertained to different score modalities. We validate the effectiveness of our method via ablation studies and comparisons with state-of-the-art alignment approaches. We demonstrate that our approach outperforms previous synchronization methods for a variety of test settings across score modalities and acoustic conditions. Our method is also robust to structural differences between the performance and score sequences, which is a common limitation of standard alignment approaches.
Audio Defect Detection in Music with Deep Networks
Feb 11, 2022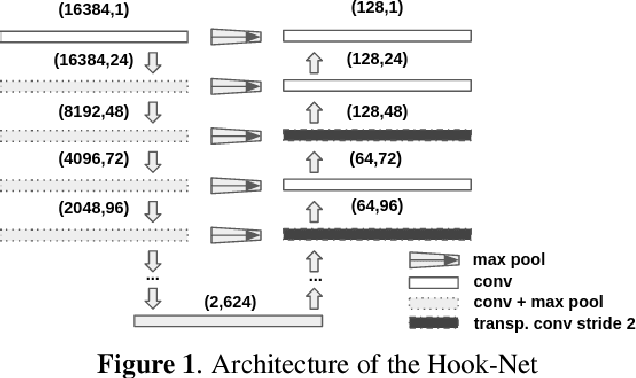
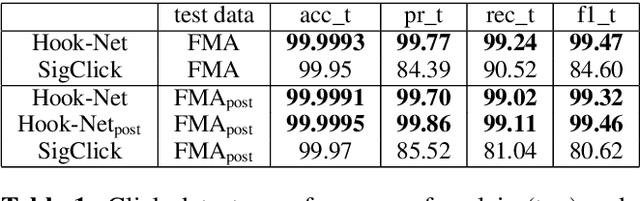
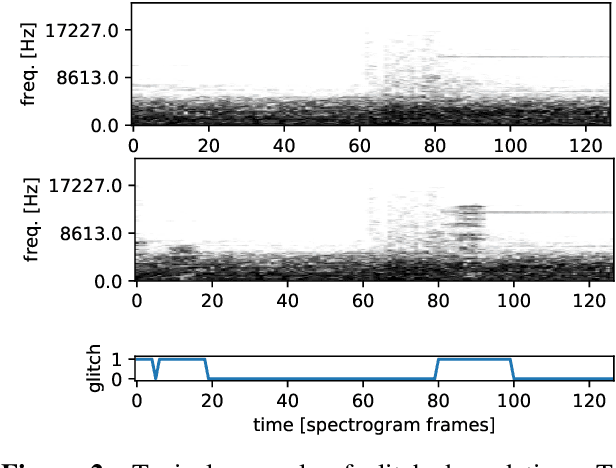
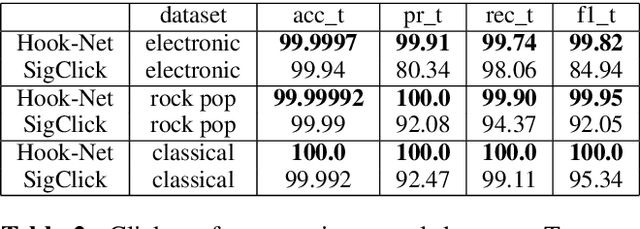
With increasing amounts of music being digitally transferred from production to distribution, automatic means of determining media quality are needed. Protection mechanisms in digital audio processing tools have not eliminated the need of production entities located downstream the distribution chain to assess audio quality and detect defects inserted further upstream. Such analysis often relies on the received audio and scarce meta-data alone. Deliberate use of artefacts such as clicks in popular music as well as more recent defects stemming from corruption in modern audio encodings call for data-centric and context sensitive solutions for detection. We present a convolutional network architecture following end-to-end encoder decoder configuration to develop detectors for two exemplary audio defects. A click detector is trained and compared to a traditional signal processing method, with a discussion on context sensitivity. Additional post-processing is used for data augmentation and workflow simulation. The ability of our models to capture variance is explored in a detector for artefacts from decompression of corrupted MP3 compressed audio. For both tasks we describe the synthetic generation of artefacts for controlled detector training and evaluation. We evaluate our detectors on the large open-source Free Music Archive (FMA) and genre-specific datasets.
* 6 pages
Structure-Aware Audio-to-Score Alignment using Progressively Dilated Convolutional Neural Networks
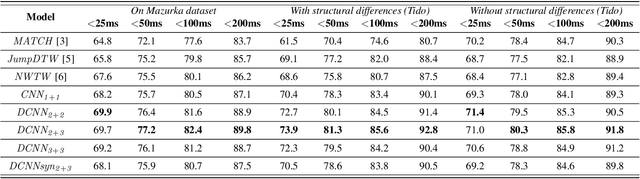
Feb 14, 2021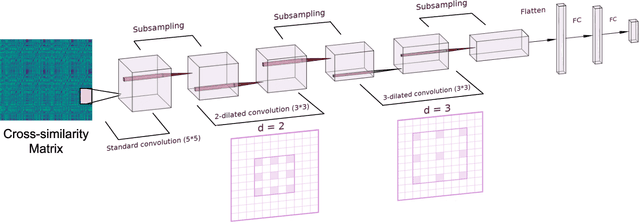
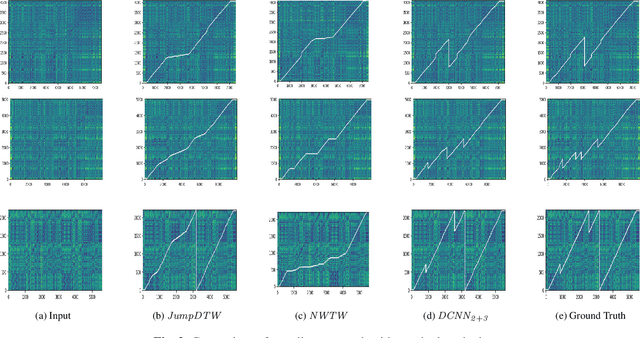
The identification of structural differences between a music performance and the score is a challenging yet integral step of audio-to-score alignment, an important subtask of music information retrieval. We present a novel method to detect such differences between the score and performance for a given piece of music using progressively dilated convolutional neural networks. Our method incorporates varying dilation rates at different layers to capture both short-term and long-term context, and can be employed successfully in the presence of limited annotated data. We conduct experiments on audio recordings of real performances that differ structurally from the score, and our results demonstrate that our models outperform standard methods for structure-aware audio-to-score alignment.