 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Balanced-Pairwise-Affinities Feature Transform
Jun 25, 2024



The Balanced-Pairwise-Affinities (BPA) feature transform is designed to upgrade the features of a set of input items to facilitate downstream matching or grouping related tasks. The transformed set encodes a rich representation of high order relations between the input features. A particular min-cost-max-flow fractional matching problem, whose entropy regularized version can be approximated by an optimal transport (OT) optimization, leads to a transform which is efficient, differentiable, equivariant, parameterless and probabilistically interpretable. While the Sinkhorn OT solver has been adapted extensively in many contexts, we use it differently by minimizing the cost between a set of features to $itself$ and using the transport plan's $rows$ as the new representation. Empirically, the transform is highly effective and flexible in its use and consistently improves networks it is inserted into, in a variety of tasks and training schemes. We demonstrate state-of-the-art results in few-shot classification, unsupervised image clustering and person re-identification. Code is available at \url{github.com/DanielShalam/BPA}.
The Self-Optimal-Transport Feature Transform
Apr 06, 2022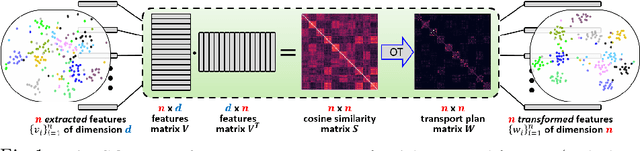


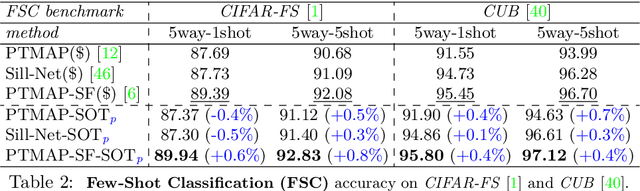
The Self-Optimal-Transport (SOT) feature transform is designed to upgrade the set of features of a data instance to facilitate downstream matching or grouping related tasks. The transformed set encodes a rich representation of high order relations between the instance features. Distances between transformed features capture their direct original similarity and their third party agreement regarding similarity to other features in the set. A particular min-cost-max-flow fractional matching problem, whose entropy regularized version can be approximated by an optimal transport (OT) optimization, results in our transductive transform which is efficient, differentiable, equivariant, parameterless and probabilistically interpretable. Empirically, the transform is highly effective and flexible in its use, consistently improving networks it is inserted into, in a variety of tasks and training schemes. We demonstrate its merits through the problem of unsupervised clustering and its efficiency and wide applicability for few-shot-classification, with state-of-the-art results, and large-scale person re-identification.