 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrust and Terror: Hazards in Text Reveal Negatively Biased Credulity and Partisan Negativity Bias
May 28, 2024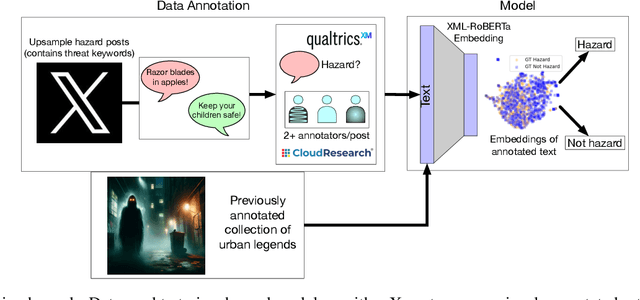
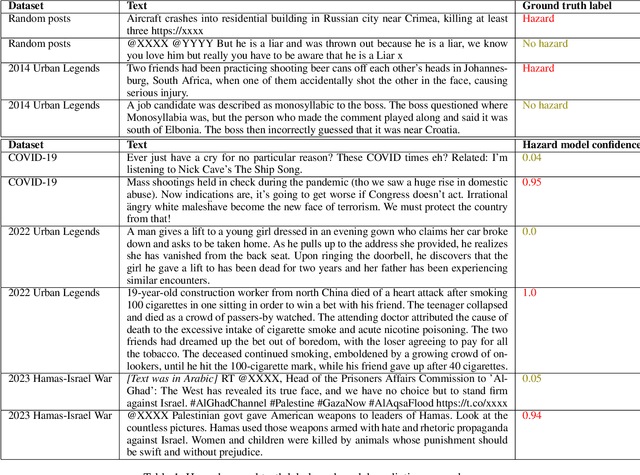
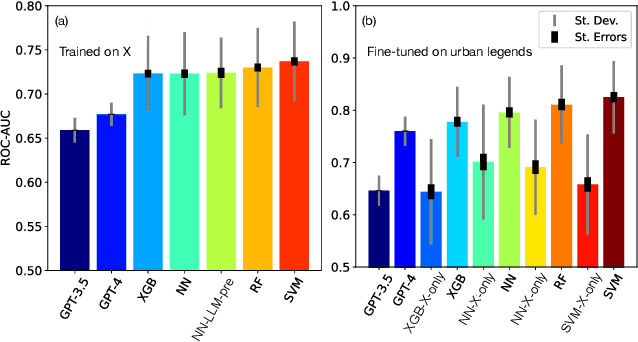
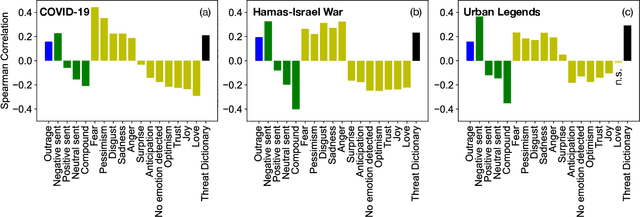
Socio-linguistic indicators of text, such as emotion or sentiment, are often extracted using neural networks in order to better understand features of social media. One indicator that is often overlooked, however, is the presence of hazards within text. Recent psychological research suggests that statements about hazards are more believable than statements about benefits (a property known as negatively biased credulity), and that political liberals and conservatives differ in how often they share hazards. Here, we develop a new model to detect information concerning hazards, trained on a new collection of annotated X posts, as well as urban legends annotated in previous work. We show that not only does this model perform well (outperforming, e.g., zero-shot human annotator proxies, such as GPT-4) but that the hazard information it extracts is not strongly correlated with other indicators, namely moral outrage, sentiment, emotions, and threat words. (That said, consonant with expectations, hazard information does correlate positively with such emotions as fear, and negatively with emotions like joy.) We then apply this model to three datasets: X posts about COVID-19, X posts about the 2023 Hamas-Israel war, and a new expanded collection of urban legends. From these data, we uncover words associated with hazards unique to each dataset as well as differences in this language between groups of users, such as conservatives and liberals, which informs what these groups perceive as hazards. We further show that information about hazards peaks in frequency after major hazard events, and therefore acts as an automated indicator of such events. Finally, we find that information about hazards is especially prevalent in urban legends, which is consistent with previous work that finds that reports of hazards are more likely to be both believed and transmitted.