 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReducing the Amount of Real World Data for Object Detector Training with Synthetic Data
Jan 31, 2022



A number of studies have investigated the training of neural networks with synthetic data for applications in the real world. The aim of this study is to quantify how much real world data can be saved when using a mixed dataset of synthetic and real world data. By modeling the relationship between the number of training examples and detection performance by a simple power law, we find that the need for real world data can be reduced by up to 70% without sacrificing detection performance. The training of object detection networks is especially enhanced by enriching the mixed dataset with classes underrepresented in the real world dataset. The results indicate that mixed datasets with real world data ratios between 5% and 20% reduce the need for real world data the most without reducing the detection performance.
Unsupervised training of a deep clustering model for multichannel blind source separation
Apr 02, 2019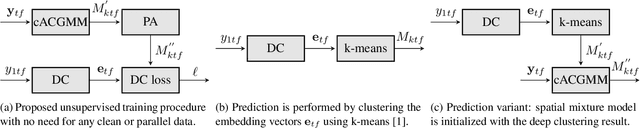
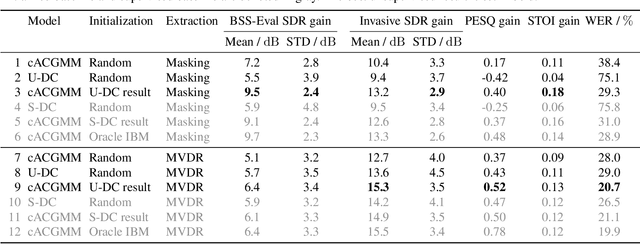
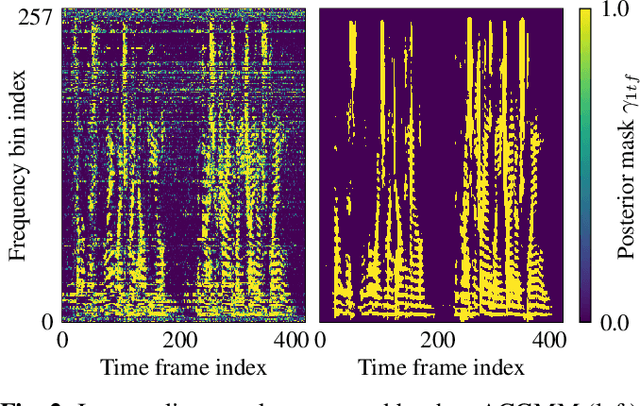
We propose a training scheme to train neural network-based source separation algorithms from scratch when parallel clean data is unavailable. In particular, we demonstrate that an unsupervised spatial clustering algorithm is sufficient to guide the training of a deep clustering system. We argue that previous work on deep clustering requires strong supervision and elaborate on why this is a limitation. We demonstrate that (a) the single-channel deep clustering system trained according to the proposed scheme alone is able to achieve a similar performance as the multi-channel teacher in terms of word error rates and (b) initializing the spatial clustering approach with the deep clustering result yields a relative word error rate reduction of 26 % over the unsupervised teacher.