 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Case Study in Text Mining: Interpreting Twitter Data From World Cup Tweets
Aug 21, 2014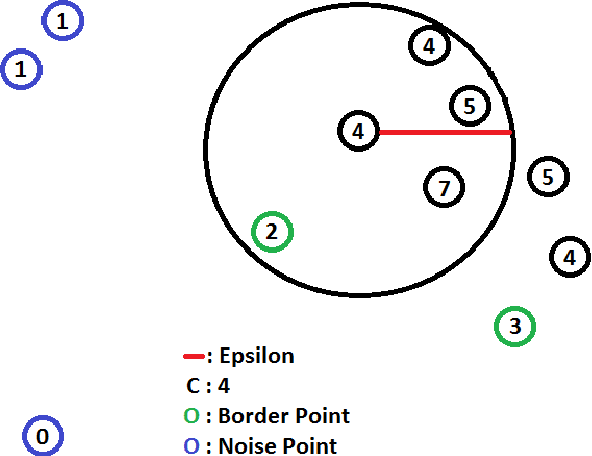
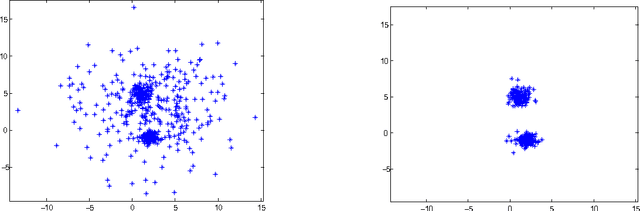
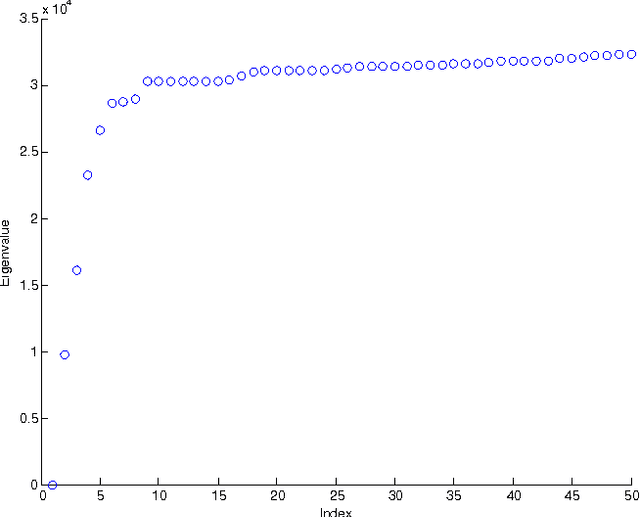
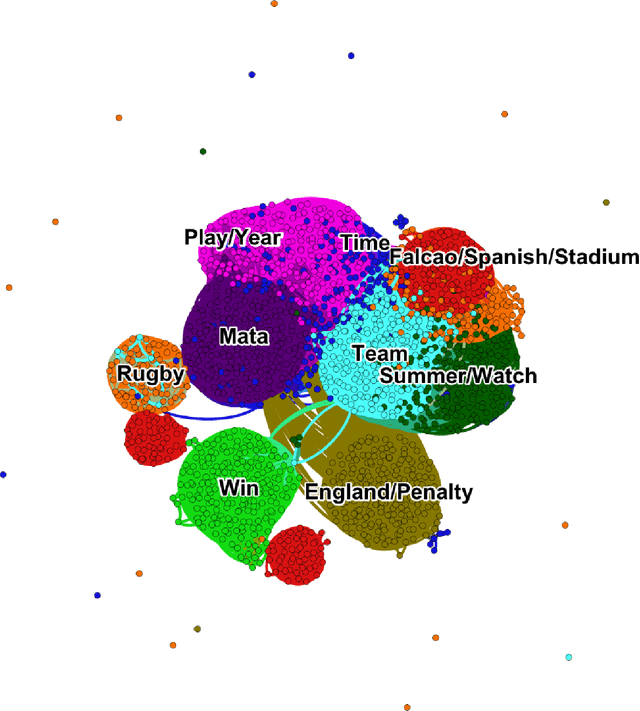
Cluster analysis is a field of data analysis that extracts underlying patterns in data. One application of cluster analysis is in text-mining, the analysis of large collections of text to find similarities between documents. We used a collection of about 30,000 tweets extracted from Twitter just before the World Cup started. A common problem with real world text data is the presence of linguistic noise. In our case it would be extraneous tweets that are unrelated to dominant themes. To combat this problem, we created an algorithm that combined the DBSCAN algorithm and a consensus matrix. This way we are left with the tweets that are related to those dominant themes. We then used cluster analysis to find those topics that the tweets describe. We clustered the tweets using k-means, a commonly used clustering algorithm, and Non-Negative Matrix Factorization (NMF) and compared the results. The two algorithms gave similar results, but NMF proved to be faster and provided more easily interpreted results. We explored our results using two visualization tools, Gephi and Wordle.