 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA framework for robotic arm pose estimation and movement prediction based on deep and extreme learning models
May 27, 2022
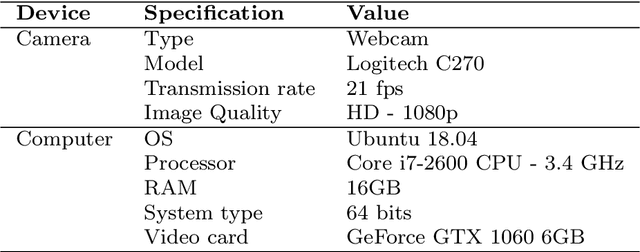


Human-robot collaboration has gained a notable prominence in Industry 4.0, as the use of collaborative robots increases efficiency and productivity in the automation process. However, it is necessary to consider the use of mechanisms that increase security in these environments, as the literature reports that risk situations may exist in the context of human-robot collaboration. One of the strategies that can be adopted is the visual recognition of the collaboration environment using machine learning techniques, which can automatically identify what is happening in the scene and what may happen in the future. In this work, we are proposing a new framework that is capable of detecting robotic arm keypoints commonly used in Industry 4.0. In addition to detecting, the proposed framework is able to predict the future movement of these robotic arms, thus providing relevant information that can be considered in the recognition of the human-robot collaboration scenario. The proposed framework is based on deep and extreme learning machine techniques. Results show that the proposed framework is capable of detecting and predicting with low error, contributing to the mitigation of risks in human-robot collaboration.
FCN-Pose: A Pruned and Quantized CNN for Robot Pose Estimation for Constrained Devices
May 26, 2022
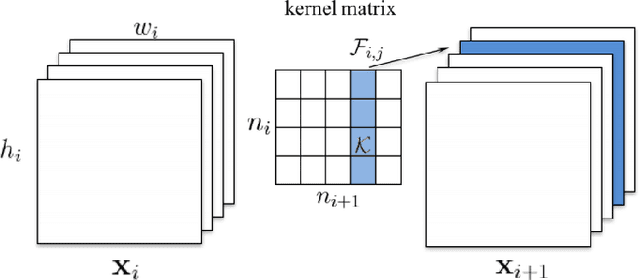
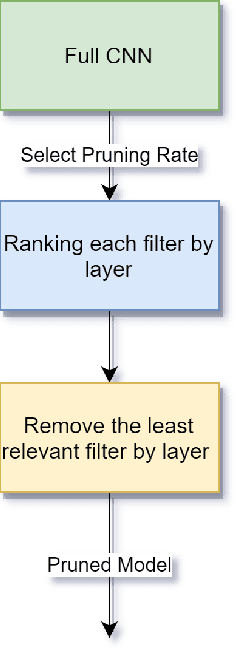
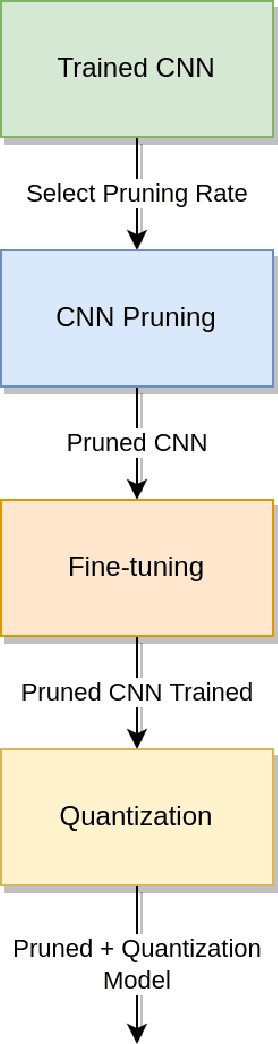
IoT devices suffer from resource limitations, such as processor, RAM, and disc storage. These limitations become more evident when handling demanding applications, such as deep learning, well-known for their heavy computational requirements. A case in point is robot pose estimation, an application that predicts the critical points of the desired image object. One way to mitigate processing and storage problems is compressing that deep learning application. This paper proposes a new CNN for the pose estimation while applying the compression techniques of pruning and quantization to reduce his demands and improve the response time. While the pruning process reduces the total number of parameters required for inference, quantization decreases the precision of the floating-point. We run the approach using a pose estimation task for a robotic arm and compare the results in a high-end device and a constrained device. As metrics, we consider the number of Floating-point Operations Per Second(FLOPS), the total of mathematical computations, the calculation of parameters, the inference time, and the number of video frames processed per second. In addition, we undertake a qualitative evaluation where we compare the output image predicted for each pruned network with the corresponding original one. We reduce the originally proposed network to a 70% pruning rate, implying an 88.86% reduction in parameters, 94.45% reduction in FLOPS, and for the disc storage, we reduced the requirement in 70% while increasing error by a mere $1\%$. With regard input image processing, this metric increases from 11.71 FPS to 41.9 FPS for the Desktop case. When using the constrained device, image processing augmented from 2.86 FPS to 10.04 FPS. The higher processing rate of image frames achieved by the proposed approach allows a much shorter response time.