 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInducing brain-relevant bias in natural language processing models
Oct 29, 2019
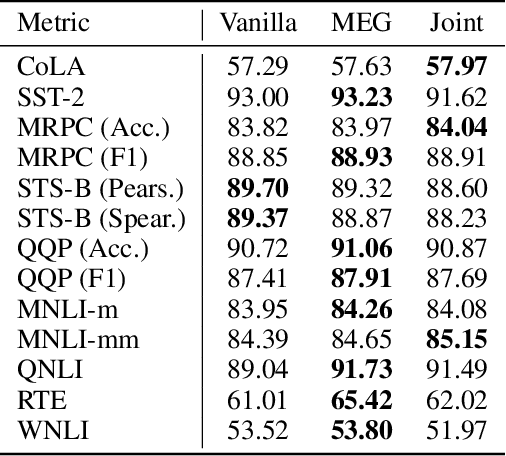
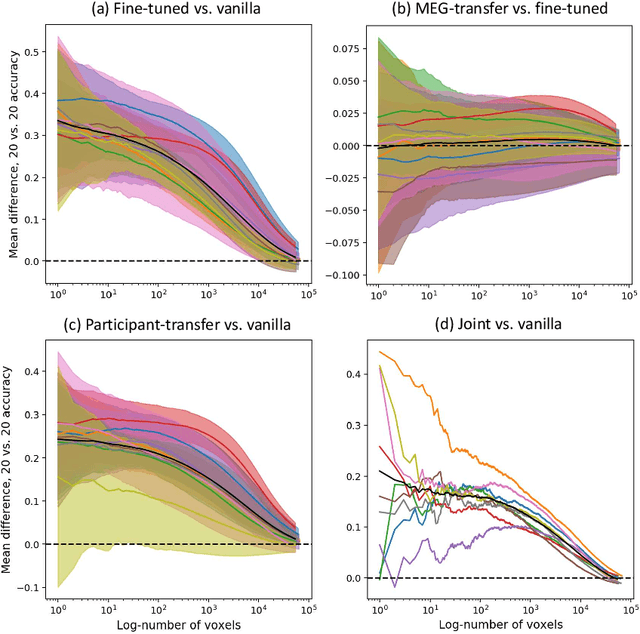
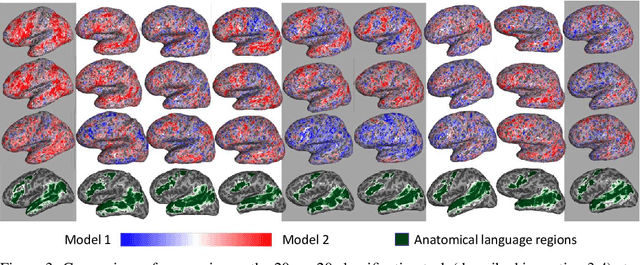
Progress in natural language processing (NLP) models that estimate representations of word sequences has recently been leveraged to improve the understanding of language processing in the brain. However, these models have not been specifically designed to capture the way the brain represents language meaning. We hypothesize that fine-tuning these models to predict recordings of brain activity of people reading text will lead to representations that encode more brain-activity-relevant language information. We demonstrate that a version of BERT, a recently introduced and powerful language model, can improve the prediction of brain activity after fine-tuning. We show that the relationship between language and brain activity learned by BERT during this fine-tuning transfers across multiple participants. We also show that, for some participants, the fine-tuned representations learned from both magnetoencephalography (MEG) and functional magnetic resonance imaging (fMRI) are better for predicting fMRI than the representations learned from fMRI alone, indicating that the learned representations capture brain-activity-relevant information that is not simply an artifact of the modality. While changes to language representations help the model predict brain activity, they also do not harm the model's ability to perform downstream NLP tasks. Our findings are notable for research on language understanding in the brain.
Understanding language-elicited EEG data by predicting it from a fine-tuned language model
Apr 02, 2019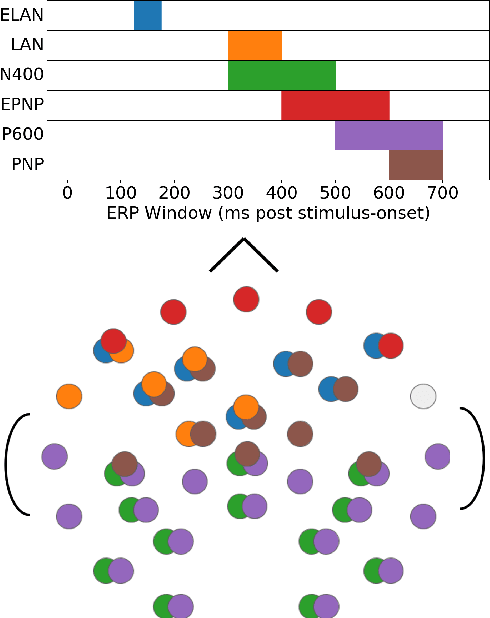
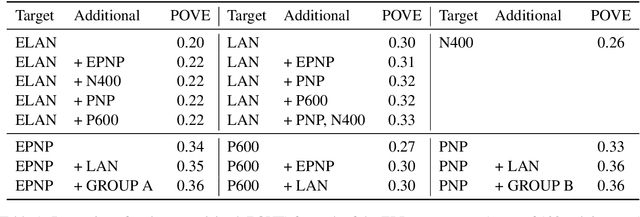

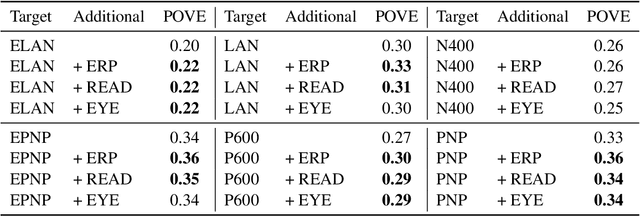
Electroencephalography (EEG) recordings of brain activity taken while participants read or listen to language are widely used within the cognitive neuroscience and psycholinguistics communities as a tool to study language comprehension. Several time-locked stereotyped EEG responses to word-presentations -- known collectively as event-related potentials (ERPs) -- are thought to be markers for semantic or syntactic processes that take place during comprehension. However, the characterization of each individual ERP in terms of what features of a stream of language trigger the response remains controversial. Improving this characterization would make ERPs a more useful tool for studying language comprehension. We take a step towards better understanding the ERPs by fine-tuning a language model to predict them. This new approach to analysis shows for the first time that all of the ERPs are predictable from embeddings of a stream of language. Prior work has only found two of the ERPs to be predictable. In addition to this analysis, we examine which ERPs benefit from sharing parameters during joint training. We find that two pairs of ERPs previously identified in the literature as being related to each other benefit from joint training, while several other pairs of ERPs that benefit from joint training are suggestive of potential relationships. Extensions of this analysis that further examine what kinds of information in the model embeddings relate to each ERP have the potential to elucidate the processes involved in human language comprehension.