Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Sparse Latent Representations with the Deep Copula Information Bottleneck
Apr 19, 2018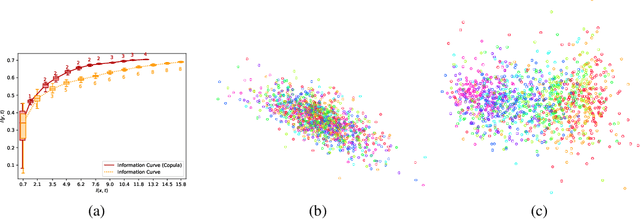
Deep latent variable models are powerful tools for representation learning. In this paper, we adopt the deep information bottleneck model, identify its shortcomings and propose a model that circumvents them. To this end, we apply a copula transformation which, by restoring the invariance properties of the information bottleneck method, leads to disentanglement of the features in the latent space. Building on that, we show how this transformation translates to sparsity of the latent space in the new model. We evaluate our method on artificial and real data.
* Conference track - ICLR 2018
* Published as a conference paper at ICLR 2018. Aleksander Wieczorek and Mario Wieser contributed equally to this work
* Published as a conference paper at ICLR 2018. Aleksander Wieczorek and Mario Wieser contributed equally to this work
Via