 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Machine Learning Catch the COVID-19 Recession?
Mar 01, 2021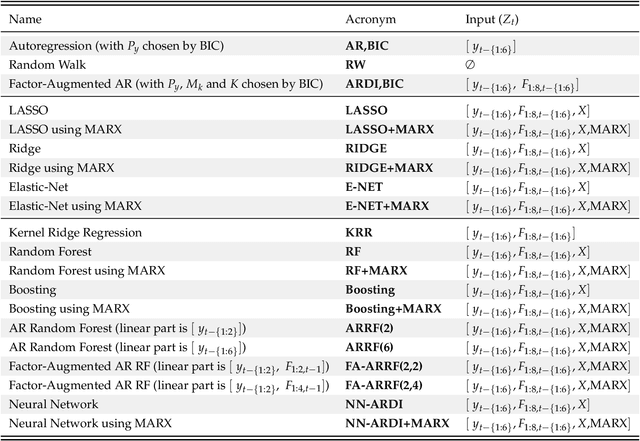
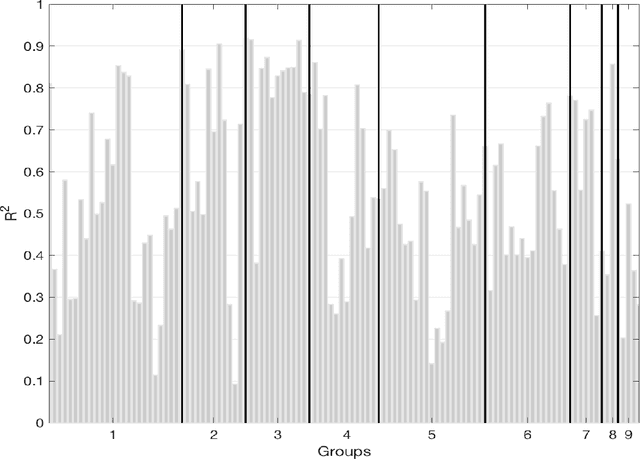
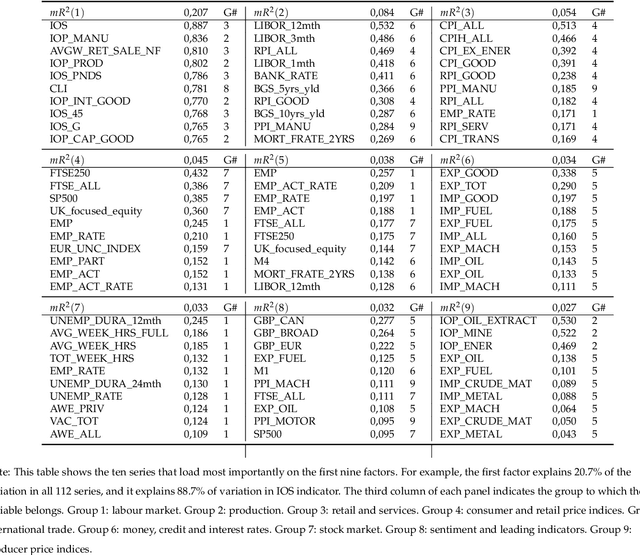
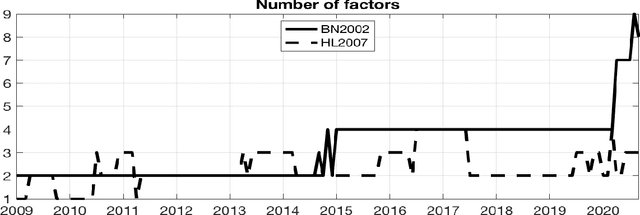
Based on evidence gathered from a newly built large macroeconomic data set for the UK, labeled UK-MD and comparable to similar datasets for the US and Canada, it seems the most promising avenue for forecasting during the pandemic is to allow for general forms of nonlinearity by using machine learning (ML) methods. But not all nonlinear ML methods are alike. For instance, some do not allow to extrapolate (like regular trees and forests) and some do (when complemented with linear dynamic components). This and other crucial aspects of ML-based forecasting in unprecedented times are studied in an extensive pseudo-out-of-sample exercise.
How is Machine Learning Useful for Macroeconomic Forecasting?
Aug 28, 2020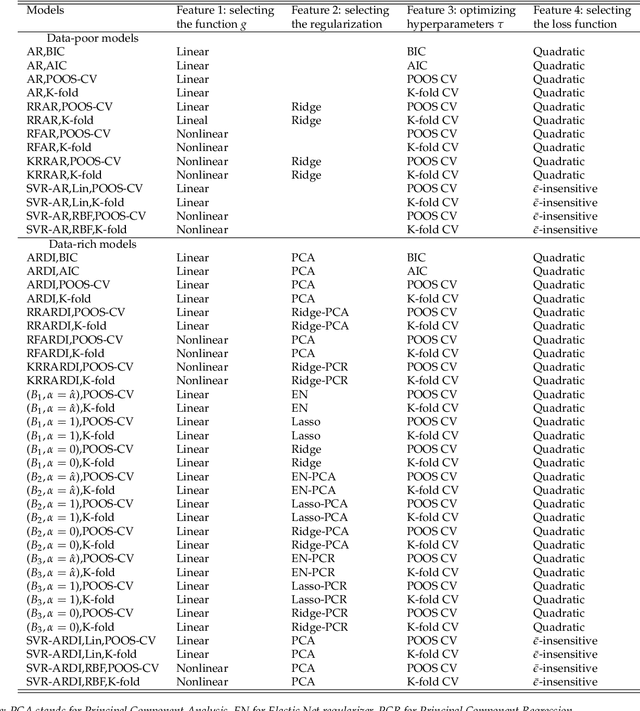
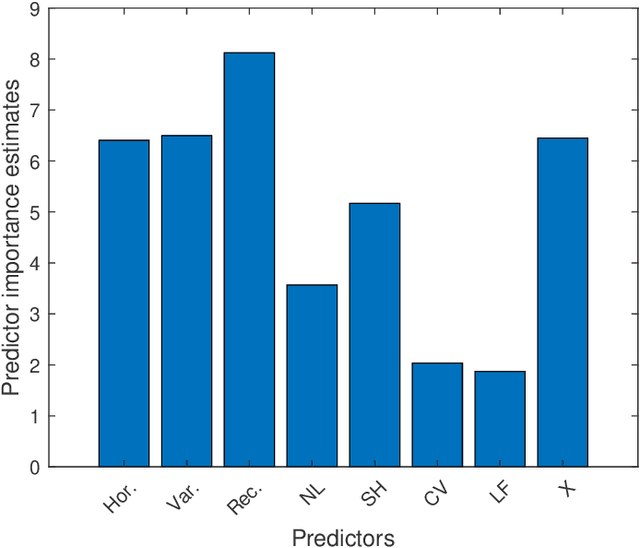
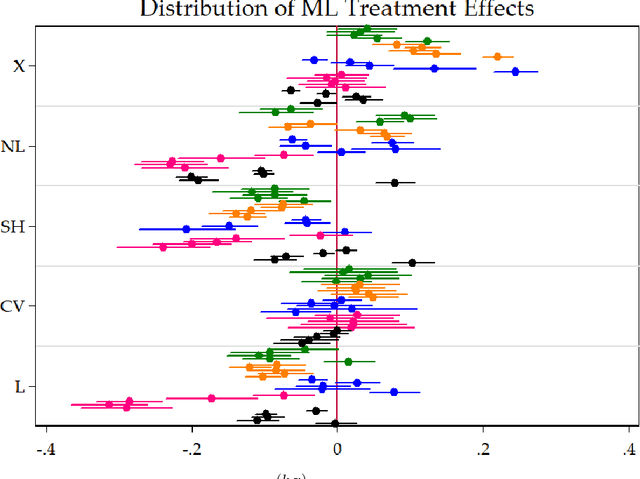
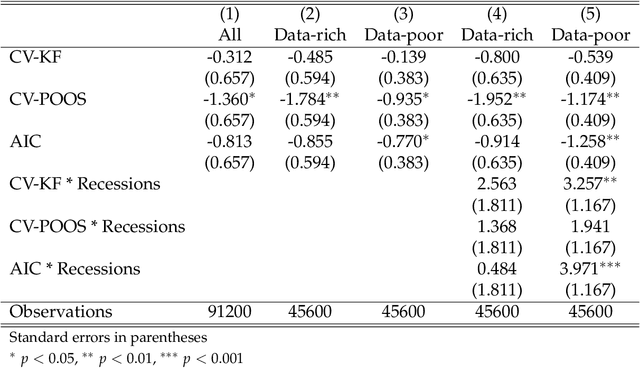
We move beyond "Is Machine Learning Useful for Macroeconomic Forecasting?" by adding the "how". The current forecasting literature has focused on matching specific variables and horizons with a particularly successful algorithm. In contrast, we study the usefulness of the underlying features driving ML gains over standard macroeconometric methods. We distinguish four so-called features (nonlinearities, regularization, cross-validation and alternative loss function) and study their behavior in both the data-rich and data-poor environments. To do so, we design experiments that allow to identify the "treatment" effects of interest. We conclude that (i) nonlinearity is the true game changer for macroeconomic prediction, (ii) the standard factor model remains the best regularization, (iii) K-fold cross-validation is the best practice and (iv) the $L_2$ is preferred to the $\bar \epsilon$-insensitive in-sample loss. The forecasting gains of nonlinear techniques are associated with high macroeconomic uncertainty, financial stress and housing bubble bursts. This suggests that Machine Learning is useful for macroeconomic forecasting by mostly capturing important nonlinearities that arise in the context of uncertainty and financial frictions.
Macroeconomic Data Transformations Matter
Aug 04, 2020



From a purely predictive standpoint, rotating the predictors' matrix in a low-dimensional linear regression setup does not alter predictions. However, when the forecasting technology either uses shrinkage or is non-linear, it does. This is precisely the fabric of the machine learning (ML) macroeconomic forecasting environment. Pre-processing of the data translates to an alteration of the regularization -- explicit or implicit -- embedded in ML algorithms. We review old transformations and propose new ones, then empirically evaluate their merits in a substantial pseudo-out-sample exercise. It is found that traditional factors should almost always be included in the feature matrix and moving average rotations of the data can provide important gains for various forecasting targets.