 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA-SFS: Semi-supervised Feature Selection based on Multi-task Self-supervision
Jul 19, 2022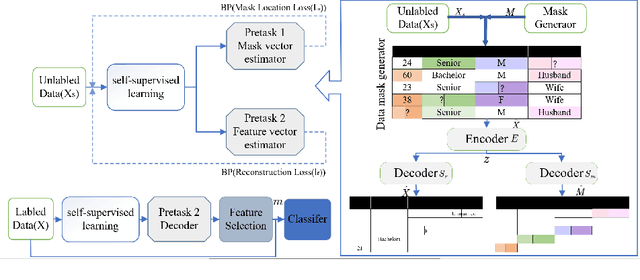

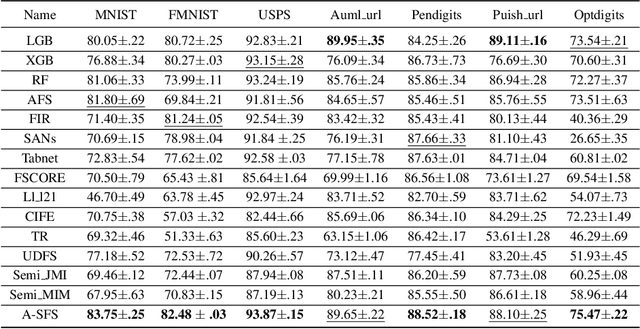
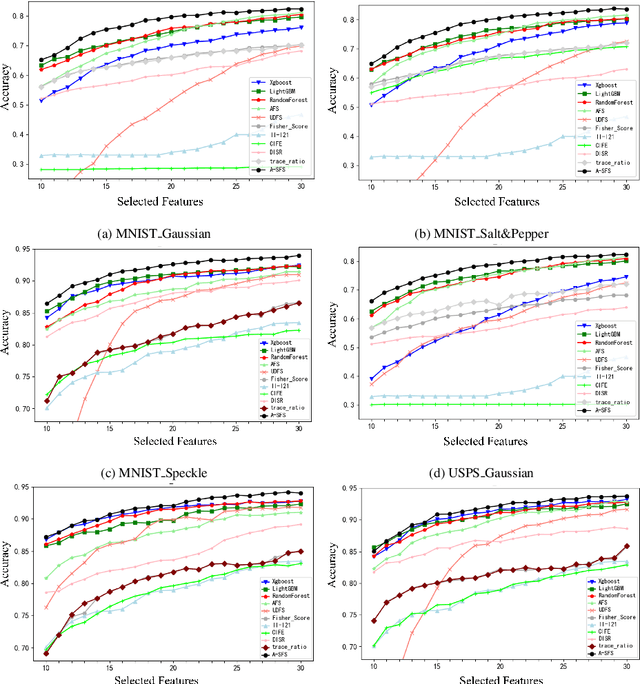
Feature selection is an important process in machine learning. It builds an interpretable and robust model by selecting the features that contribute the most to the prediction target. However, most mature feature selection algorithms, including supervised and semi-supervised, fail to fully exploit the complex potential structure between features. We believe that these structures are very important for the feature selection process, especially when labels are lacking and data is noisy. To this end, we innovatively introduce a deep learning-based self-supervised mechanism into feature selection problems, namely batch-Attention-based Self-supervision Feature Selection(A-SFS). Firstly, a multi-task self-supervised autoencoder is designed to uncover the hidden structure among features with the support of two pretext tasks. Guided by the integrated information from the multi-self-supervised learning model, a batch-attention mechanism is designed to generate feature weights according to batch-based feature selection patterns to alleviate the impacts introduced by a handful of noisy data. This method is compared to 14 major strong benchmarks, including LightGBM and XGBoost. Experimental results show that A-SFS achieves the highest accuracy in most datasets. Furthermore, this design significantly reduces the reliance on labels, with only 1/10 labeled data needed to achieve the same performance as those state of art baselines. Results show that A-SFS is also most robust to the noisy and missing data.