 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffects of Reward Shaping on Curriculum Learning in Goal Conditioned Tasks
Jun 06, 2022
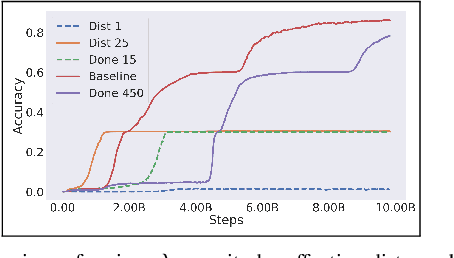
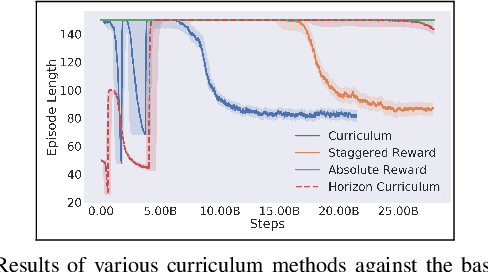
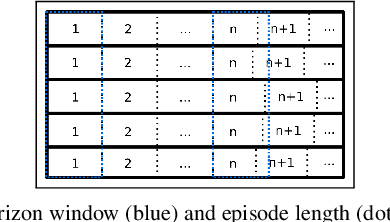
Real-time control for robotics is a popular research area in the reinforcement learning (RL) community. Through the use of techniques such as reward shaping, researchers have managed to train online agents across a multitude of domains. Despite these advances, solving goal-oriented tasks still require complex architectural changes or heavy constraints to be placed on the problem. To address this issue, recent works have explored how curriculum learning can be used to separate a complex task into sequential sub-goals, hence enabling the learning of a problem that may otherwise be too difficult to learn from scratch. In this article, we present how curriculum learning, reward shaping, and a high number of efficiently parallelized environments can be coupled together to solve the problem of multiple cube stacking. Finally, we extend the best configuration identified on a higher complexity environment with differently shaped objects.
Comparison of non-linear activation functions for deep neural networks on MNIST classification task
Apr 08, 2018
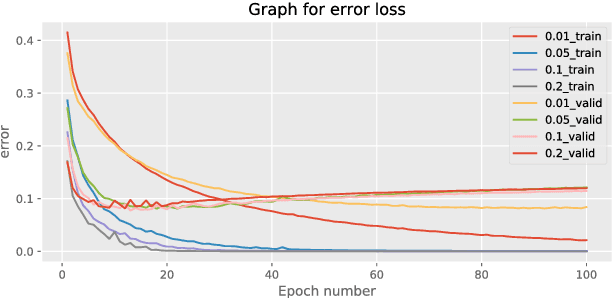

Activation functions play a key role in neural networks so it becomes fundamental to understand their advantages and disadvantages in order to achieve better performances. This paper will first introduce common types of non linear activation functions that are alternative to the well known sigmoid function and then evaluate their characteristics. Moreover deeper neural networks will be analysed because they positively influence the final performances compared to shallower networks. They also strictly depend on the weight initialisation hence the effect of drawing weights from Gaussian and uniform distribution will be analysed making particular attention on how the number of incoming and outgoing connection to a node influence the whole network.