 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSample-optimal learning of quantum states using gentle measurements
May 30, 2025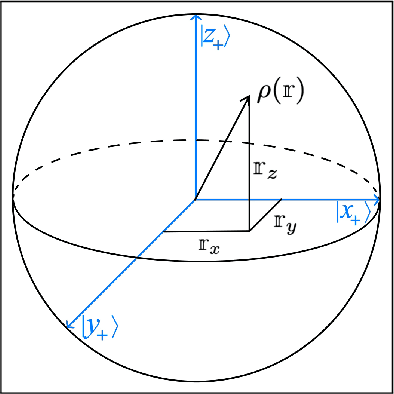
Gentle measurements of quantum states do not entirely collapse the initial state. Instead, they provide a post-measurement state at a prescribed trace distance $\alpha$ from the initial state together with a random variable used for quantum learning of the initial state. We introduce here the class of $\alpha-$locally-gentle measurements ($\alpha-$LGM) on a finite dimensional quantum system which are product measurements on product states and prove a strong quantum Data-Processing Inequality (qDPI) on this class using an improved relation between gentleness and quantum differential privacy. We further show a gentle quantum Neyman-Pearson lemma which implies that our qDPI is asymptotically optimal (for small $\alpha$). This inequality is employed to show that the necessary number of quantum states for prescribed accuracy $\epsilon$ is of order $1/(\epsilon^2 \alpha^2)$ for both quantum tomography and quantum state certification. Finally, we propose an $\alpha-$LGM called quantum Label Switch that attains these bounds. It is a general implementable method to turn any two-outcome measurement into an $\alpha-$LGM.
Nonparametric spectral density estimation using interactive mechanisms under local differential privacy
Apr 01, 2025
We address the problem of nonparametric estimation of the spectral density for a centered stationary Gaussian time series under local differential privacy constraints. Specifically, we propose new interactive privacy mechanisms for three tasks: estimating a single covariance coefficient, estimating the spectral density at a fixed frequency, and estimating the entire spectral density function. Our approach achieves faster rates through a two-stage process: we apply first the Laplace mechanism to the truncated value and then use the former privatized sample to gain knowledge on the dependence mechanism in the time series. For spectral densities belonging to H\"older and Sobolev smoothness classes, we demonstrate that our estimators improve upon the non-interactive mechanism of Kroll (2024) for small privacy parameter $\alpha$, since the pointwise rates depend on $n\alpha^2$ instead of $n\alpha^4$. Moreover, we show that the rate $(n\alpha^4)^{-1}$ is optimal for estimating a covariance coefficient with non-interactive mechanisms. However, the $L_2$ rate of our interactive estimator is slower than the pointwise rate. We show how to use these estimators to provide a bona-fide locally differentially private covariance matrix estimator.
Off-the-grid prediction and testing for mixtures of translated features
Dec 02, 2022We consider a model where a signal (discrete or continuous) is observed with an additive Gaussian noise process. The signal is issued from a linear combination of a finite but increasing number of translated features. The features are continuously parameterized by their location and depend on some scale parameter. First, we extend previous prediction results for off-the-grid estimators by taking into account here that the scale parameter may vary. The prediction bounds are analogous, but we improve the minimal distance between two consecutive features locations in order to achieve these bounds. Next, we propose a goodness-of-fit test for the model and give non-asymptotic upper bounds of the testing risk and of the minimax separation rate between two distinguishable signals. In particular, our test encompasses the signal detection framework. We deduce upper bounds on the minimal energy, expressed as the 2-norm of the linear coefficients, to successfully detect a signal in presence of noise. The general model considered in this paper is a non-linear extension of the classical high-dimensional regression model. It turns out that, in this framework, our upper bound on the minimax separation rate matches (up to a logarithmic factor) the lower bound on the minimax separation rate for signal detection in the high dimensional linear model associated to a fixed dictionary of features. We also propose a procedure to test whether the features of the observed signal belong to a given finite collection under the assumption that the linear coefficients may vary, but do not change to opposite signs under the null hypothesis. A non-asymptotic upper bound on the testing risk is given. We illustrate our results on the spikes deconvolution model with Gaussian features on the real line and with the Dirichlet kernel, frequently used in the compressed sensing literature, on the torus.
Simultaneous off-the-grid learning of mixtures issued from a continuous dictionary
Oct 27, 2022

In this paper we observe a set, possibly a continuum, of signals corrupted by noise. Each signal is a finite mixture of an unknown number of features belonging to a continuous dictionary. The continuous dictionary is parametrized by a real non-linear parameter. We shall assume that the signals share an underlying structure by saying that the union of active features in the whole dataset is finite. We formulate regularized optimization problems to estimate simultaneously the linear coefficients in the mixtures and the non-linear parameters of the features. The optimization problems are composed of a data fidelity term and a (l1 , Lp)-penalty. We prove high probability bounds on the prediction errors associated to our estimators. The proof is based on the existence of certificate functions. Following recent works on the geometry of off-the-grid methods, we show that such functions can be constructed provided the parameters of the active features are pairwise separated by a constant with respect to a Riemannian metric. When the number of signals is finite and the noise is assumed Gaussian, we give refinements of our results for p = 1 and p = 2 using tail bounds on suprema of Gaussian and $\chi$2 random processes. When p = 2, our prediction error reaches the rates obtained by the Group-Lasso estimator in the multi-task linear regression model.
Off-the-grid learning of sparse mixtures from a continuous dictionary
Jun 29, 2022We consider a general non-linear model where the signal is a finite mixture of an unknown, possibly increasing, number of features issued from a continuous dictionary parameterized by a real nonlinear parameter. The signal is observed with Gaussian (possibly correlated) noise in either a continuous or a discrete setup. We propose an off-the-grid optimization method, that is, a method which does not use any discretization scheme on the parameter space, to estimate both the non-linear parameters of the features and the linear parameters of the mixture. We use recent results on the geometry of off-the-grid methods to give minimal separation on the true underlying non-linear parameters such that interpolating certificate functions can be constructed. Using also tail bounds for suprema of Gaussian processes we bound the prediction error with high probability. Assuming that the certificate functions can be constructed, our prediction error bound is up to log --factors similar to the rates attained by the Lasso predictor in the linear regression model. We also establish convergence rates that quantify with high probability the quality of estimation for both the linear and the non-linear parameters.
Locally differentially private estimation of nonlinear functionals of discrete distributions
Jul 08, 2021
We study the problem of estimating non-linear functionals of discrete distributions in the context of local differential privacy. The initial data $x_1,\ldots,x_n \in [K]$ are supposed i.i.d. and distributed according to an unknown discrete distribution $p = (p_1,\ldots,p_K)$. Only $\alpha$-locally differentially private (LDP) samples $z_1,...,z_n$ are publicly available, where the term 'local' means that each $z_i$ is produced using one individual attribute $x_i$. We exhibit privacy mechanisms (PM) that are interactive (i.e. they are allowed to use already published confidential data) or non-interactive. We describe the behavior of the quadratic risk for estimating the power sum functional $F_{\gamma} = \sum_{k=1}^K p_k^{\gamma}$, $\gamma >0$ as a function of $K, \, n$ and $\alpha$. In the non-interactive case, we study two plug-in type estimators of $F_{\gamma}$, for all $\gamma >0$, that are similar to the MLE analyzed by Jiao et al. (2017) in the multinomial model. However, due to the privacy constraint the rates we attain are slower and similar to those obtained in the Gaussian model by Collier et al. (2020). In the interactive case, we introduce for all $\gamma >1$ a two-step procedure which attains the faster parametric rate $(n \alpha^2)^{-1/2}$ when $\gamma \geq 2$. We give lower bounds results over all $\alpha$-LDP mechanisms and all estimators using the private samples.
Locally private non-asymptotic testing of discrete distributions is faster using interactive mechanisms
May 26, 2020
We find separation rates for testing multinomial or more general discrete distributions under the constraint of local differential privacy. We construct efficient randomized algorithms and test procedures, in both the case where only non-interactive privacy mechanisms are allowed and also in the case where all sequentially interactive privacy mechanisms are allowed. The separation rates are faster in the latter case. We prove general information theoretical bounds that allow us to establish the optimality of our algorithms among all pairs of privacy mechanisms and test procedures, in most usual cases. Considered examples include testing uniform, polynomially and exponentially decreasing distributions.
Classification under local differential privacy
Dec 10, 2019We consider the binary classification problem in a setup that preserves the privacy of the original sample. We provide a privacy mechanism that is locally differentially private and then construct a classifier based on the private sample that is universally consistent in Euclidean spaces. Under stronger assumptions, we establish the minimax rates of convergence of the excess risk and see that they are slower than in the case when the original sample is available.