 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPACE-IDEAS: A Dataset for Salient Information Detection in Space Innovation
Mar 25, 2024



Detecting salient parts in text using natural language processing has been widely used to mitigate the effects of information overflow. Nevertheless, most of the datasets available for this task are derived mainly from academic publications. We introduce SPACE-IDEAS, a dataset for salient information detection from innovation ideas related to the Space domain. The text in SPACE-IDEAS varies greatly and includes informal, technical, academic and business-oriented writing styles. In addition to a manually annotated dataset we release an extended version that is annotated using a large generative language model. We train different sentence and sequential sentence classifiers, and show that the automatically annotated dataset can be leveraged using multitask learning to train better classifiers.
Textual Entailment for Effective Triple Validation in Object Prediction
Jan 29, 2024Knowledge base population seeks to expand knowledge graphs with facts that are typically extracted from a text corpus. Recently, language models pretrained on large corpora have been shown to contain factual knowledge that can be retrieved using cloze-style strategies. Such approach enables zero-shot recall of facts, showing competitive results in object prediction compared to supervised baselines. However, prompt-based fact retrieval can be brittle and heavily depend on the prompts and context used, which may produce results that are unintended or hallucinatory.We propose to use textual entailment to validate facts extracted from language models through cloze statements. Our results show that triple validation based on textual entailment improves language model predictions in different training regimes. Furthermore, we show that entailment-based triple validation is also effective to validate candidate facts extracted from other sources including existing knowledge graphs and text passages where named entities are recognized.
Generating Quizzes to Support Training on Quality Management and Assurance in Space Science and Engineering
Oct 07, 2022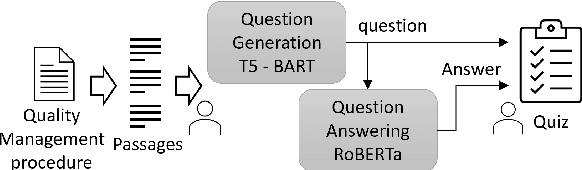



Quality management and assurance is key for space agencies to guarantee the success of space missions, which are high-risk and extremely costly. In this paper, we present a system to generate quizzes, a common resource to evaluate the effectiveness of training sessions, from documents about quality assurance procedures in the Space domain. Our system leverages state of the art auto-regressive models like T5 and BART to generate questions, and a RoBERTa model to extract answers for such questions, thus verifying their suitability.
SpaceQA: Answering Questions about the Design of Space Missions and Space Craft Concepts
Oct 07, 2022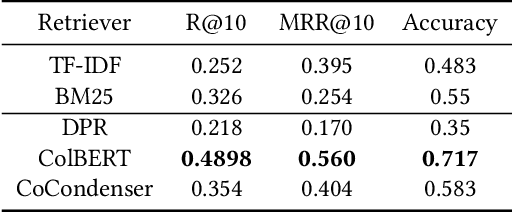
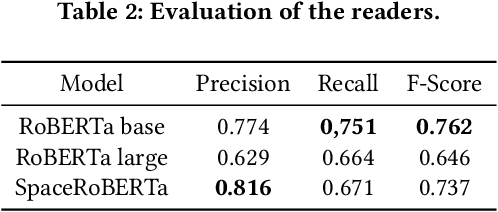
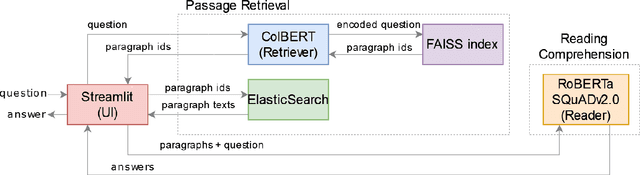
We present SpaceQA, to the best of our knowledge the first open-domain QA system in Space mission design. SpaceQA is part of an initiative by the European Space Agency (ESA) to facilitate the access, sharing and reuse of information about Space mission design within the agency and with the public. We adopt a state-of-the-art architecture consisting of a dense retriever and a neural reader and opt for an approach based on transfer learning rather than fine-tuning due to the lack of domain-specific annotated data. Our evaluation on a test set produced by ESA is largely consistent with the results originally reported by the evaluated retrievers and confirms the need of fine tuning for reading comprehension. As of writing this paper, ESA is piloting SpaceQA internally.