 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnified Local and Global Attention Interaction Modeling for Vision Transformers
Dec 25, 2024We present a novel method that extends the self-attention mechanism of a vision transformer (ViT) for more accurate object detection across diverse datasets. ViTs show strong capability for image understanding tasks such as object detection, segmentation, and classification. This is due in part to their ability to leverage global information from interactions among visual tokens. However, the self-attention mechanism in ViTs are limited because they do not allow visual tokens to exchange local or global information with neighboring features before computing global attention. This is problematic because tokens are treated in isolation when attending (matching) to other tokens, and valuable spatial relationships are overlooked. This isolation is further compounded by dot-product similarity operations that make tokens from different semantic classes appear visually similar. To address these limitations, we introduce two modifications to the traditional self-attention framework; a novel aggressive convolution pooling strategy for local feature mixing, and a new conceptual attention transformation to facilitate interaction and feature exchange between semantic concepts. Experimental results demonstrate that local and global information exchange among visual features before self-attention significantly improves performance on challenging object detection tasks and generalizes across multiple benchmark datasets and challenging medical datasets. We publish source code and a novel dataset of cancerous tumors (chimeric cell clusters).
Multiscale Detection of Cancerous Tissue in High Resolution Slide Scans
Oct 01, 2020
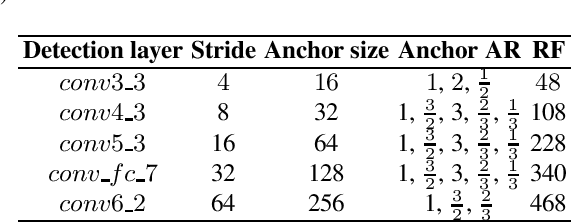


We present an algorithm for multi-scale tumor (chimeric cell) detection in high resolution slide scans. The broad range of tumor sizes in our dataset pose a challenge for current Convolutional Neural Networks (CNN) which often fail when image features are very small (8 pixels). Our approach modifies the effective receptive field at different layers in a CNN so that objects with a broad range of varying scales can be detected in a single forward pass. We define rules for computing adaptive prior anchor boxes which we show are solvable under the equal proportion interval principle. Two mechanisms in our CNN architecture alleviate the effects of non-discriminative features prevalent in our data - a foveal detection algorithm that incorporates a cascade residual-inception module and a deconvolution module with additional context information. When integrated into a Single Shot MultiBox Detector (SSD), these additions permit more accurate detection of small-scale objects. The results permit efficient real-time analysis of medical images in pathology and related biomedical research fields.