 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVectorized Scenario Description and Motion Prediction for Scenario-Based Testing
Feb 02, 2023



Automated vehicles (AVs) are tested in diverse scenarios, typically specified by parameters such as velocities, distances, or curve radii. To describe scenarios uniformly independent of such parameters, this paper proposes a vectorized scenario description defined by the road geometry and vehicles' trajectories. Data of this form are generated for three scenarios, merged, and used to train the motion prediction model VectorNet, allowing to predict an AV's trajectory for unseen scenarios. Predicting scenario evaluation metrics, VectorNet partially achieves lower errors than regression models that separately process the three scenarios' data. However, for comprehensive generalization, sufficient variance in the training data must be ensured. Thus, contrary to existing methods, our proposed method can merge diverse scenarios' data and exploit spatial and temporal nuances in the vectorized scenario description. As a result, data from specified test scenarios and real-world scenarios can be compared and combined for (predictive) analyses and scenario selection.
Transfer Importance Sampling $\unicode{x2013}$ How Testing Automated Vehicles in Multiple Test Setups Helps With the Bias-Variance Tradeoff
Apr 15, 2022
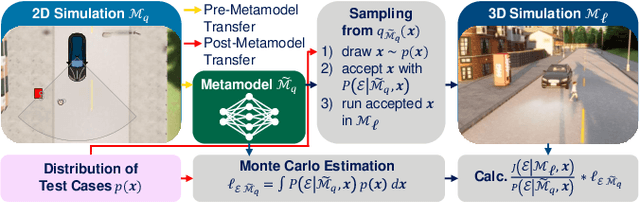
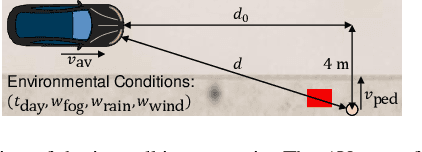
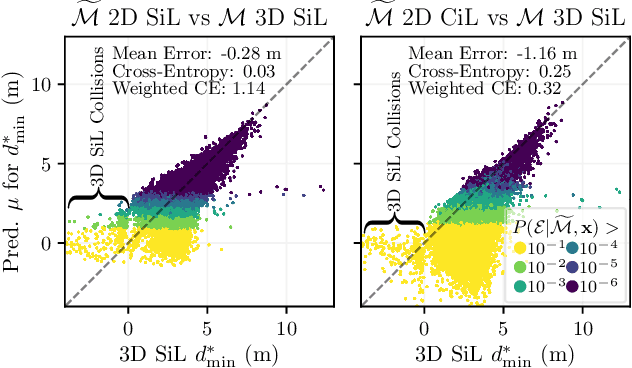
The promise of increased road safety is a key motivator for the development of automated vehicles (AV). Yet, demonstrating that an AV is as safe as, or even safer than, a human-driven vehicle has proven to be challenging. Should an AV be examined purely virtually, allowing large numbers of fully controllable tests? Or should it be tested under real environmental conditions on a proving ground? Since different test setups have different strengths and weaknesses, it is still an open question how virtual and real tests should be combined. On the way to answer this question, this paper proposes transfer importance sampling (TIS), a risk estimation method linking different test setups. Fusing the concepts of transfer learning and importance sampling, TIS uses a scalable, cost-effective test setup to comprehensively explore an AV's behavior. The insights gained then allow parameterizing tests in a more trustworthy test setup accurately reflecting risks. We show that when using a trustworthy test setup alone is prohibitively expensive, linking it to a scalable test setup can increase efficiency $\unicode{x2013}$ without sacrificing the result's validity. Thus, the test setups' individual deficiencies are compensated for by their systematic linkage.