 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage Models as Emotional Classifiers for Textual Conversations
Aug 27, 2020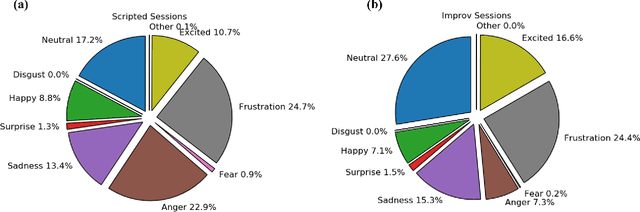
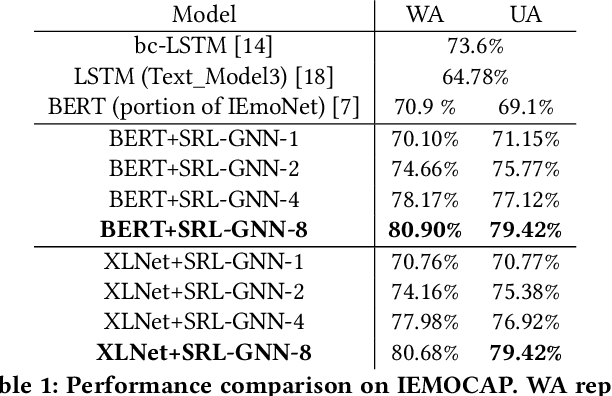


Emotions play a critical role in our everyday lives by altering how we perceive, process and respond to our environment. Affective computing aims to instill in computers the ability to detect and act on the emotions of human actors. A core aspect of any affective computing system is the classification of a user's emotion. In this study we present a novel methodology for classifying emotion in a conversation. At the backbone of our proposed methodology is a pre-trained Language Model (LM), which is supplemented by a Graph Convolutional Network (GCN) that propagates information over the predicate-argument structure identified in an utterance. We apply our proposed methodology on the IEMOCAP and Friends data sets, achieving state-of-the-art performance on the former and a higher accuracy on certain emotional labels on the latter. Furthermore, we examine the role context plays in our methodology by altering how much of the preceding conversation the model has access to when making a classification.
Repurposing TREC-COVID Annotations to Answer the Key Questions of CORD-19
Aug 27, 2020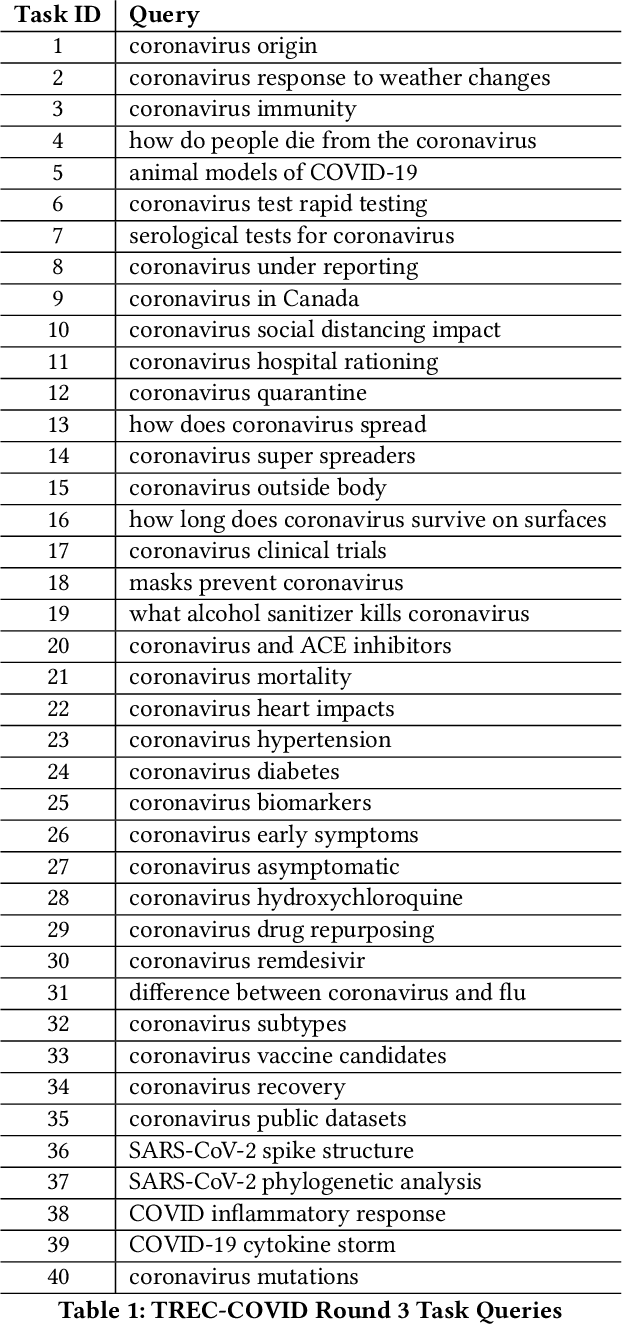



The novel coronavirus disease 2019 (COVID-19) began in Wuhan, China in late 2019 and to date has infected over 14M people worldwide, resulting in over 750,000 deaths. On March 10, 2020 the World Health Organization (WHO) declared the outbreak a global pandemic. Many academics and researchers, not restricted to the medical domain, began publishing papers describing new discoveries. However, with the large influx of publications, it was hard for these individuals to sift through the large amount of data and make sense of the findings. The White House and a group of industry research labs, lead by the Allen Institute for AI, aggregated over 200,000 journal articles related to a variety of coronaviruses and tasked the community with answering key questions related to the corpus, releasing the dataset as CORD-19. The information retrieval (IR) community repurposed the journal articles within CORD-19 to more closely resemble a classic TREC-style competition, dubbed TREC-COVID, with human annotators providing relevancy judgements at the end of each round of competition. Seeing the related endeavors, we set out to repurpose the relevancy annotations for TREC-COVID tasks to identify journal articles in CORD-19 which are relevant to the key questions posed by CORD-19. A BioBERT model trained on this repurposed dataset prescribes relevancy annotations for CORD-19 tasks that have an overall agreement of 0.4430 with majority human annotations in terms of Cohen's kappa. We present the methodology used to construct the new dataset and describe the decision process used throughout.