 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaking Reinforcement Learning Work on Swimmer
Aug 25, 2022
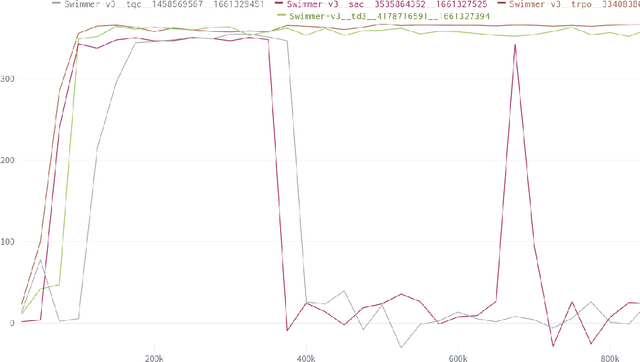
The SWIMMER environment is a standard benchmark in reinforcement learning (RL). In particular, it is often used in papers comparing or combining RL methods with direct policy search methods such as genetic algorithms or evolution strategies. A lot of these papers report poor performance on SWIMMER from RL methods and much better performance from direct policy search methods. In this technical report we show that the low performance of RL methods on SWIMMER simply comes from the inadequate tuning of an important hyper-parameter, the discount factor. Furthermore we show that, by setting this hyper-parameter to a correct value, the issue can be easily fixed. Finally, for a set of often used RL algorithms, we provide a set of successful hyper-parameters obtained with the Stable Baselines3 library and its RL Zoo.