 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransformer-Based Approaches for Sensor-Based Human Activity Recognition: Opportunities and Challenges
Oct 17, 2024



Transformers have excelled in natural language processing and computer vision, paving their way to sensor-based Human Activity Recognition (HAR). Previous studies show that transformers outperform their counterparts exclusively when they harness abundant data or employ compute-intensive optimization algorithms. However, neither of these scenarios is viable in sensor-based HAR due to the scarcity of data in this field and the frequent need to perform training and inference on resource-constrained devices. Our extensive investigation into various implementations of transformer-based versus non-transformer-based HAR using wearable sensors, encompassing more than 500 experiments, corroborates these concerns. We observe that transformer-based solutions pose higher computational demands, consistently yield inferior performance, and experience significant performance degradation when quantized to accommodate resource-constrained devices. Additionally, transformers demonstrate lower robustness to adversarial attacks, posing a potential threat to user trust in HAR.
Automatic Map Update Using Dashcam Videos
Sep 24, 2021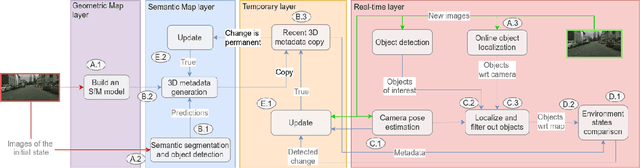

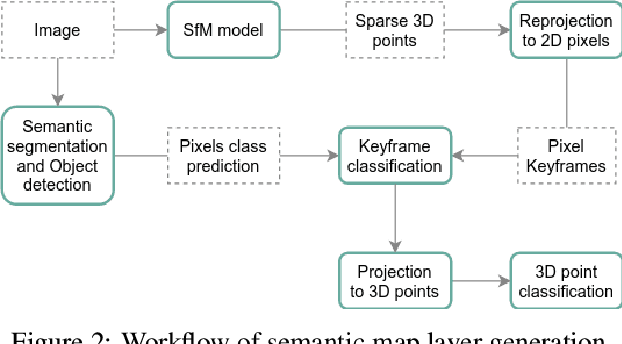

Autonomous driving requires 3D maps that provide accurate and up-to-date information about semantic landmarks. Due to the wider availability and lower cost of cameras compared with laser scanners, vision-based mapping has attracted much attention from academia and industry. Among the existing solutions, Structure-from-Motion (SfM) technology has proved to be feasible for building 3D maps from crowdsourced data, since it allows unordered images as input. Previous works on SfM have mainly focused on issues related to building 3D point clouds and calculating camera poses, leaving the issues of automatic change detection and localization open. We propose in this paper an SfM-based solution for automatic map update, with a focus on real-time change detection and localization. Our solution builds on comparison of semantic map data (e.g. types and locations of traffic signs). Through a novel design of the pixel-wise 3D localization algorithm, our system can locate the objects detected from 2D images in a 3D space, utilizing sparse SfM point clouds. Experiments with dashcam videos collected from two urban areas prove that the system is able to locate visible traffic signs in front along the driving direction with a median distance error of 1.52 meters. Moreover, it can detect up to 80\% of the changes with a median distance error of 2.21 meters. The result analysis also shows the potential of significantly improving the system performance in the future by increasing the accuracy of the background technology in use, including in particularly the object detection and point cloud geo-registration algorithms.