 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransformer and Hybrid Deep Learning Based Models for Machine-Generated Text Detection
May 28, 2024

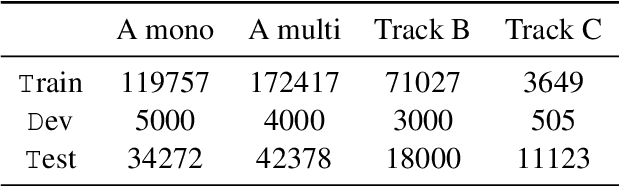
This paper describes the approach of the UniBuc - NLP team in tackling the SemEval 2024 Task 8: Multigenerator, Multidomain, and Multilingual Black-Box Machine-Generated Text Detection. We explored transformer-based and hybrid deep learning architectures. For subtask B, our transformer-based model achieved a strong \textbf{second-place} out of $77$ teams with an accuracy of \textbf{86.95\%}, demonstrating the architecture's suitability for this task. However, our models showed overfitting in subtask A which could potentially be fixed with less fine-tunning and increasing maximum sequence length. For subtask C (token-level classification), our hybrid model overfit during training, hindering its ability to detect transitions between human and machine-generated text.
Automated Text Identification Using CNN and Training Dynamics
May 18, 2024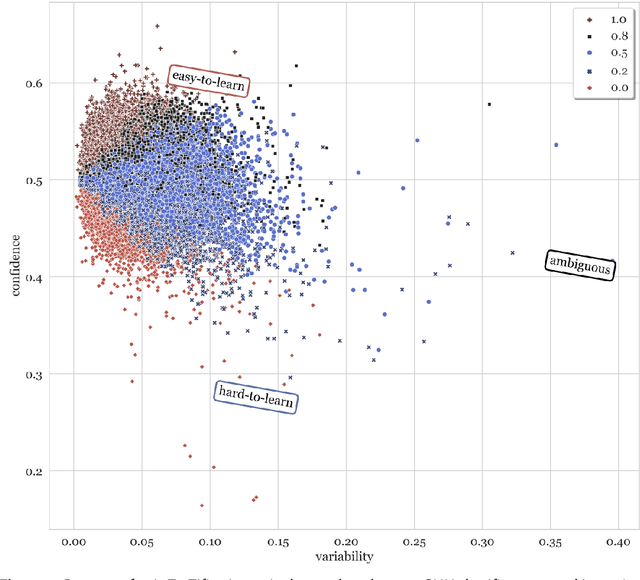

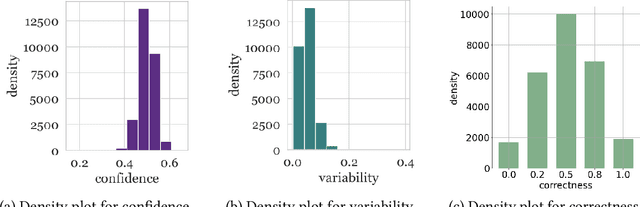
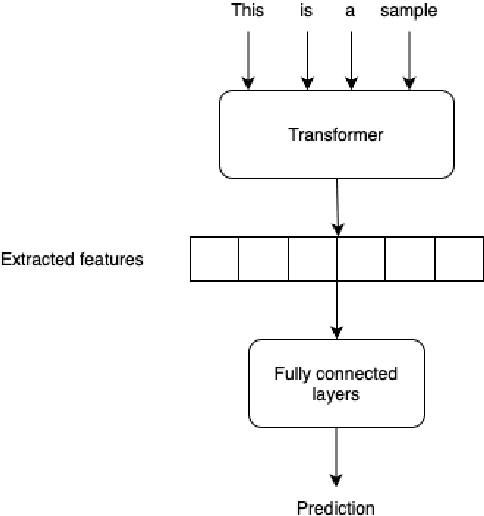
We used Data Maps to model and characterize the AuTexTification dataset. This provides insights about the behaviour of individual samples during training across epochs (training dynamics). We characterized the samples across 3 dimensions: confidence, variability and correctness. This shows the presence of 3 regions: easy-to-learn, ambiguous and hard-to-learn examples. We used a classic CNN architecture and found out that training the model only on a subset of ambiguous examples improves the model's out-of-distribution generalization.
Designing NLP Systems That Adapt to Diverse Worldviews
May 18, 2024Natural Language Inference (NLI) is foundational for evaluating language understanding in AI. However, progress has plateaued, with models failing on ambiguous examples and exhibiting poor generalization. We argue that this stems from disregarding the subjective nature of meaning, which is intrinsically tied to an individual's \textit{weltanschauung} (which roughly translates to worldview). Existing NLP datasets often obscure this by aggregating labels or filtering out disagreement. We propose a perspectivist approach: building datasets that capture annotator demographics, values, and justifications for their labels. Such datasets would explicitly model diverse worldviews. Our initial experiments with a subset of the SBIC dataset demonstrate that even limited annotator metadata can improve model performance.
Transformer based neural networks for emotion recognition in conversations
May 18, 2024This paper outlines the approach of the ISDS-NLP team in the SemEval 2024 Task 10: Emotion Discovery and Reasoning its Flip in Conversation (EDiReF). For Subtask 1 we obtained a weighted F1 score of 0.43 and placed 12 in the leaderboard. We investigate two distinct approaches: Masked Language Modeling (MLM) and Causal Language Modeling (CLM). For MLM, we employ pre-trained BERT-like models in a multilingual setting, fine-tuning them with a classifier to predict emotions. Experiments with varying input lengths, classifier architectures, and fine-tuning strategies demonstrate the effectiveness of this approach. Additionally, we utilize Mistral 7B Instruct V0.2, a state-of-the-art model, applying zero-shot and few-shot prompting techniques. Our findings indicate that while Mistral shows promise, MLMs currently outperform them in sentence-level emotion classification.