Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Text Identification Using CNN and Training Dynamics
Paper and Code
May 18, 2024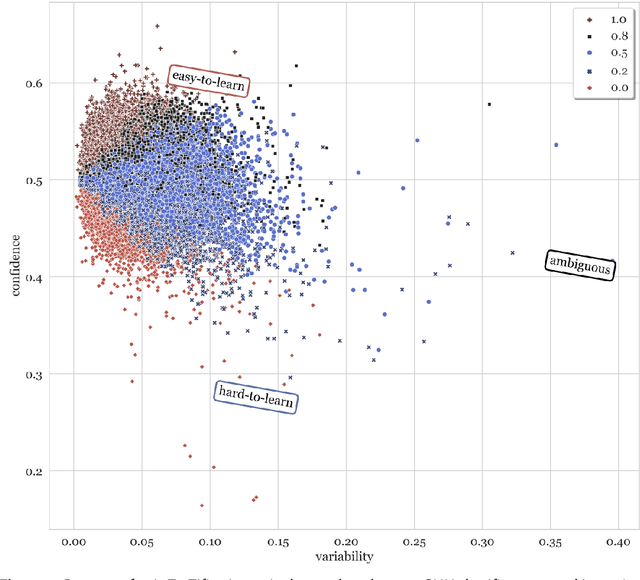

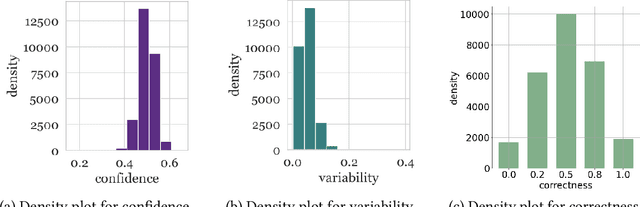
We used Data Maps to model and characterize the AuTexTification dataset. This provides insights about the behaviour of individual samples during training across epochs (training dynamics). We characterized the samples across 3 dimensions: confidence, variability and correctness. This shows the presence of 3 regions: easy-to-learn, ambiguous and hard-to-learn examples. We used a classic CNN architecture and found out that training the model only on a subset of ambiguous examples improves the model's out-of-distribution generalization.
* Vol-3496, 2023, 4-8
View paper on