 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnergy-Efficient Federated Edge Learning with Streaming Data: A Lyapunov Optimization Approach
May 20, 2024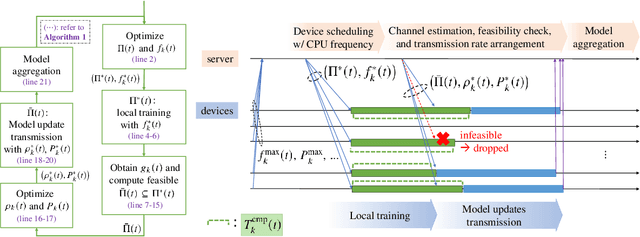
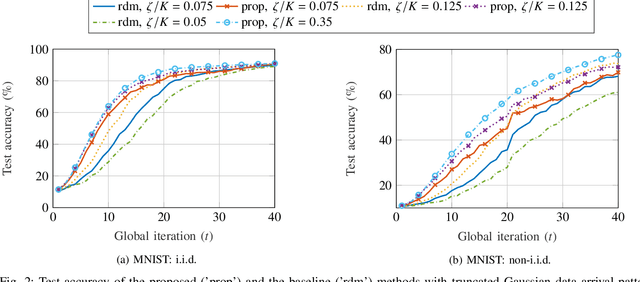
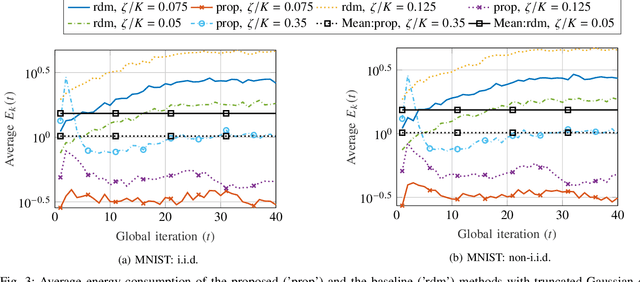
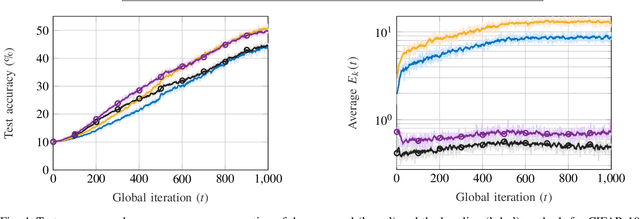
Federated learning (FL) has received significant attention in recent years for its advantages in efficient training of machine learning models across distributed clients without disclosing user-sensitive data. Specifically, in federated edge learning (FEEL) systems, the time-varying nature of wireless channels introduces inevitable system dynamics in the communication process, thereby affecting training latency and energy consumption. In this work, we further consider a streaming data scenario where new training data samples are randomly generated over time at edge devices. Our goal is to develop a dynamic scheduling and resource allocation algorithm to address the inherent randomness in data arrivals and resource availability under long-term energy constraints. To achieve this, we formulate a stochastic network optimization problem and use the Lyapunov drift-plus-penalty framework to obtain a dynamic resource management design. Our proposed algorithm makes adaptive decisions on device scheduling, computational capacity adjustment, and allocation of bandwidth and transmit power in every round. We provide convergence analysis for the considered setting with heterogeneous data and time-varying objective functions, which supports the rationale behind our proposed scheduling design. The effectiveness of our scheme is verified through simulation results, demonstrating improved learning performance and energy efficiency as compared to baseline schemes.
Dynamic Scheduling for Federated Edge Learning with Streaming Data
May 02, 2023In this work, we consider a Federated Edge Learning (FEEL) system where training data are randomly generated over time at a set of distributed edge devices with long-term energy constraints. Due to limited communication resources and latency requirements, only a subset of devices is scheduled for participating in the local training process in every iteration. We formulate a stochastic network optimization problem for designing a dynamic scheduling policy that maximizes the time-average data importance from scheduled user sets subject to energy consumption and latency constraints. Our proposed algorithm based on the Lyapunov optimization framework outperforms alternative methods without considering time-varying data importance, especially when the generation of training data shows strong temporal correlation.
Scheduling and Aggregation Design for Asynchronous Federated Learning over Wireless Networks
Dec 14, 2022Federated Learning (FL) is a collaborative machine learning (ML) framework that combines on-device training and server-based aggregation to train a common ML model among distributed agents. In this work, we propose an asynchronous FL design with periodic aggregation to tackle the straggler issue in FL systems. Considering limited wireless communication resources, we investigate the effect of different scheduling policies and aggregation designs on the convergence performance. Driven by the importance of reducing the bias and variance of the aggregated model updates, we propose a scheduling policy that jointly considers the channel quality and training data representation of user devices. The effectiveness of our channel-aware data-importance-based scheduling policy, compared with state-of-the-art methods proposed for synchronous FL, is validated through simulations. Moreover, we show that an "age-aware" aggregation weighting design can significantly improve the learning performance in an asynchronous FL setting.
Device Scheduling and Update Aggregation Policies for Asynchronous Federated Learning
Jul 23, 2021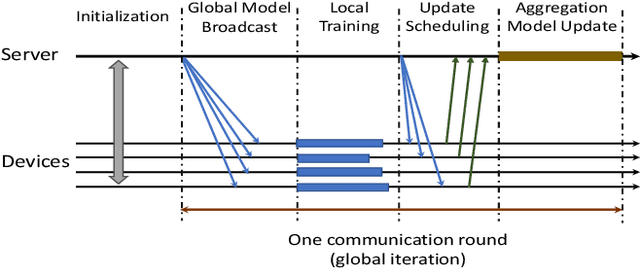
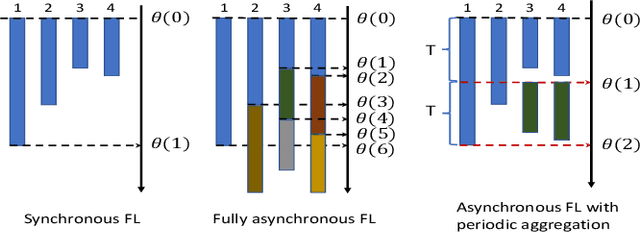
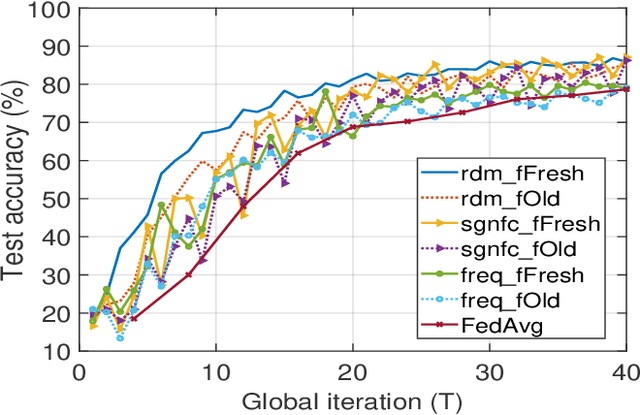
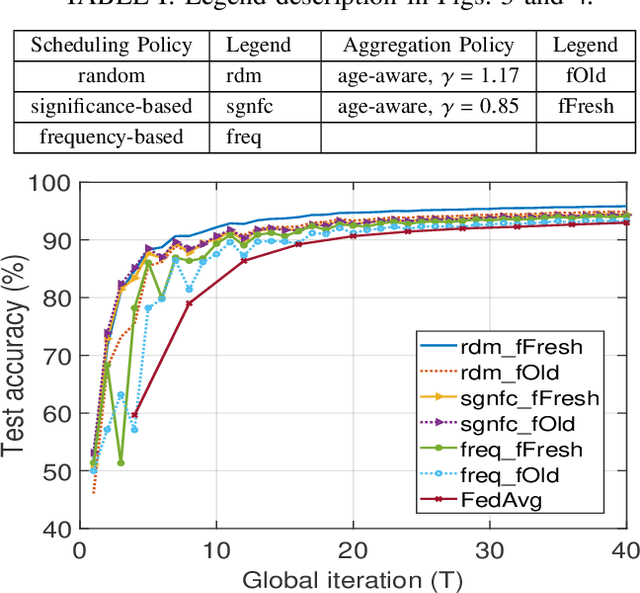
Federated Learning (FL) is a newly emerged decentralized machine learning (ML) framework that combines on-device local training with server-based model synchronization to train a centralized ML model over distributed nodes. In this paper, we propose an asynchronous FL framework with periodic aggregation to eliminate the straggler issue in FL systems. For the proposed model, we investigate several device scheduling and update aggregation policies and compare their performances when the devices have heterogeneous computation capabilities and training data distributions. From the simulation results, we conclude that the scheduling and aggregation design for asynchronous FL can be rather different from the synchronous case. For example, a norm-based significance-aware scheduling policy might not be efficient in an asynchronous FL setting, and an appropriate "age-aware" weighting design for the model aggregation can greatly improve the learning performance of such systems.