 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Robust Neural Vocoding for Speech Generation: A Survey
Dec 05, 2019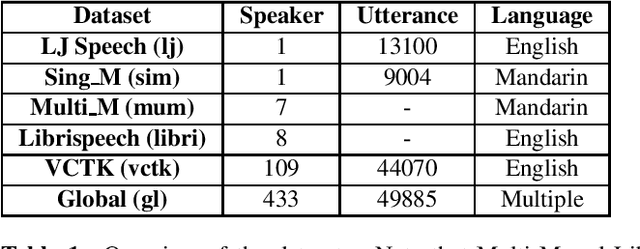

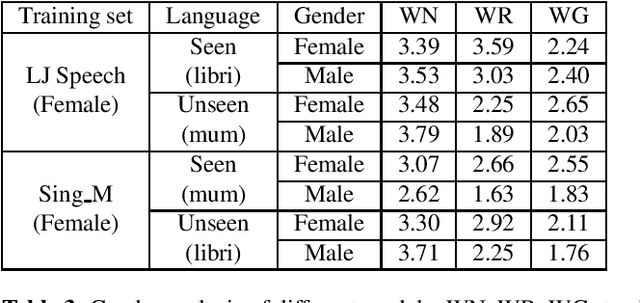
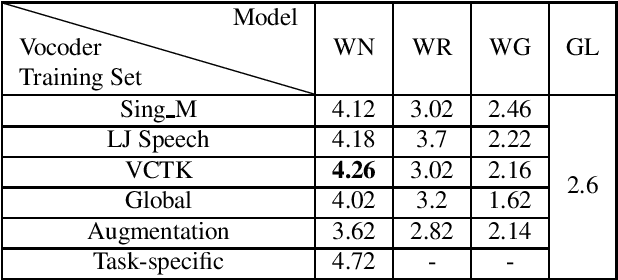
Recently, neural vocoders have been widely used in speech synthesis tasks, including text-to-speech and voice conversion. However, in the encounter of data distribution mismatch between training and inference, neural vocoders trained on real data often degrade in voice quality for unseen scenarios. In this paper, we train three commonly used neural vocoders, including WaveNet, WaveRNN, and WaveGlow, alternately on five different datasets. To study the robustness of neural vocoders, we evaluate the models using acoustic features from seen/unseen speakers, seen/unseen languages, a text-to-speech model, and a voice conversion model. In this work, we found that WaveNet is more robust than WaveRNN, especially in the face of inconsistency between training and testing data. Through our experiments, we show that WaveNet is more suitable for text-to-speech models, and WaveRNN more suitable for voice conversion applications. Furthermore, we present results with considerable reference value of subjective human evaluation for future studies.