 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTaylorGAN: Neighbor-Augmented Policy Update for Sample-Efficient Natural Language Generation
Nov 27, 2020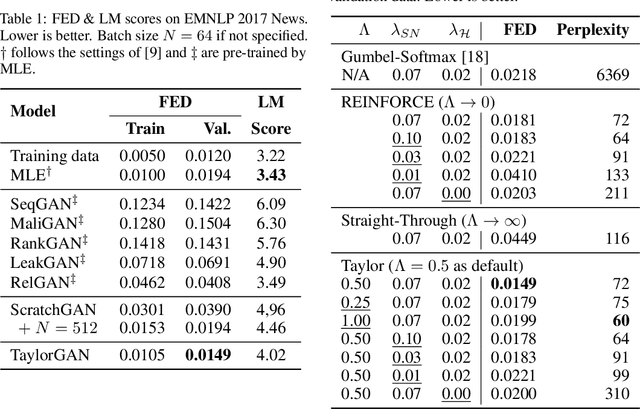
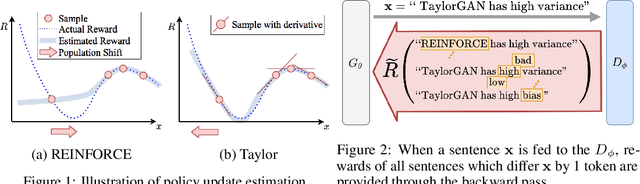

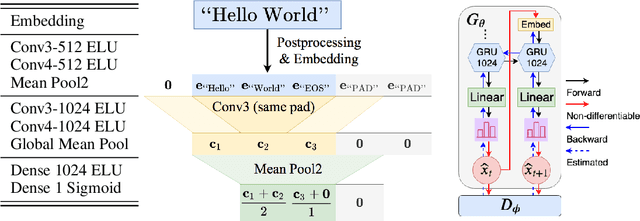
Score function-based natural language generation (NLG) approaches such as REINFORCE, in general, suffer from low sample efficiency and training instability problems. This is mainly due to the non-differentiable nature of the discrete space sampling and thus these methods have to treat the discriminator as a black box and ignore the gradient information. To improve the sample efficiency and reduce the variance of REINFORCE, we propose a novel approach, TaylorGAN, which augments the gradient estimation by off-policy update and the first-order Taylor expansion. This approach enables us to train NLG models from scratch with smaller batch size -- without maximum likelihood pre-training, and outperforms existing GAN-based methods on multiple metrics of quality and diversity. The source code and data are available at https://github.com/MiuLab/TaylorGAN