 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph Attention Network for Predicting Duration of Large-Scale Power Outages Induced by Natural Disasters
Nov 14, 2025



Natural disasters such as hurricanes, wildfires, and winter storms have induced large-scale power outages in the U.S., resulting in tremendous economic and societal impacts. Accurately predicting power outage recovery and impact is key to resilience of power grid. Recent advances in machine learning offer viable frameworks for estimating power outage duration from geospatial and weather data. However, three major challenges are inherent to the task in a real world setting: spatial dependency of the data, spatial heterogeneity of the impact, and moderate event data. We propose a novel approach to estimate the duration of severe weather-induced power outages through Graph Attention Networks (GAT). Our network uses a simple structure from unsupervised pre-training, followed by semi-supervised learning. We use field data from four major hurricanes affecting $501$ counties in eight Southeastern U.S. states. The model exhibits an excellent performance ($>93\%$ accuracy) and outperforms the existing methods XGBoost, Random Forest, GCN and simple GAT by $2\% - 15\%$ in both the overall performance and class-wise accuracy.
Learning Geo-Temporal Non-Stationary Failure and Recovery of Power Distribution
Apr 29, 2013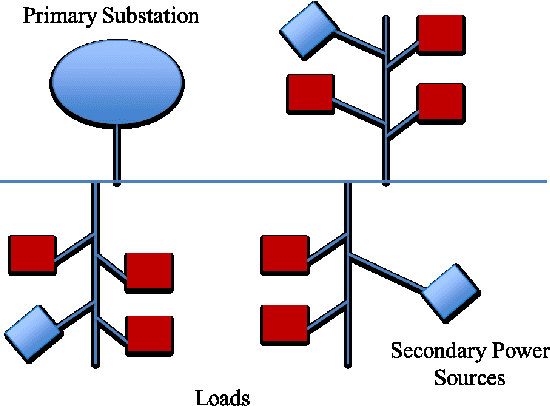
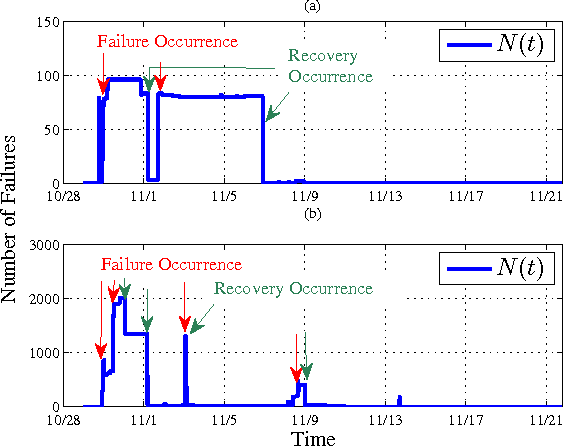
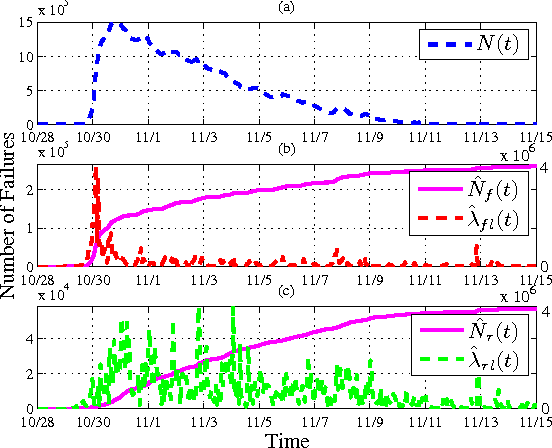
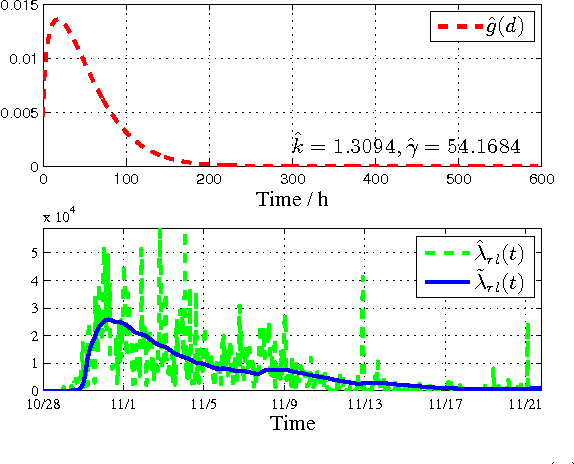
Smart energy grid is an emerging area for new applications of machine learning in a non-stationary environment. Such a non-stationary environment emerges when large-scale failures occur at power distribution networks due to external disturbances such as hurricanes and severe storms. Power distribution networks lie at the edge of the grid, and are especially vulnerable to external disruptions. Quantifiable approaches are lacking and needed to learn non-stationary behaviors of large-scale failure and recovery of power distribution. This work studies such non-stationary behaviors in three aspects. First, a novel formulation is derived for an entire life cycle of large-scale failure and recovery of power distribution. Second, spatial-temporal models of failure and recovery of power distribution are developed as geo-location based multivariate non-stationary GI(t)/G(t)/Infinity queues. Third, the non-stationary spatial-temporal models identify a small number of parameters to be learned. Learning is applied to two real-life examples of large-scale disruptions. One is from Hurricane Ike, where data from an operational network is exact on failures and recoveries. The other is from Hurricane Sandy, where aggregated data is used for inferring failure and recovery processes at one of the impacted areas. Model parameters are learned using real data. Two findings emerge as results of learning: (a) Failure rates behave similarly at the two different provider networks for two different hurricanes but differently at the geographical regions. (b) Both rapid- and slow-recovery are present for Hurricane Ike but only slow recovery is shown for a regional distribution network from Hurricane Sandy.
Joint Approximation of Information and Distributed Link-Scheduling Decisions in Wireless Networks
Mar 04, 2012


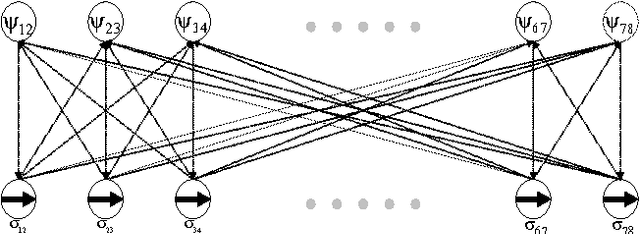
For a large multi-hop wireless network, nodes are preferable to make distributed and localized link-scheduling decisions with only interactions among a small number of neighbors. However, for a slowly decaying channel and densely populated interferers, a small size neighborhood often results in nontrivial link outages and is thus insufficient for making optimal scheduling decisions. A question arises how to deal with the information outside a neighborhood in distributed link-scheduling. In this work, we develop joint approximation of information and distributed link scheduling. We first apply machine learning approaches to model distributed link-scheduling with complete information. We then characterize the information outside a neighborhood in form of residual interference as a random loss variable. The loss variable is further characterized by either a Mean Field approximation or a normal distribution based on the Lyapunov central limit theorem. The approximated information outside a neighborhood is incorporated in a factor graph. This results in joint approximation and distributed link-scheduling in an iterative fashion. Link-scheduling decisions are first made at each individual node based on the approximated loss variables. Loss variables are then updated and used for next link-scheduling decisions. The algorithm repeats between these two phases until convergence. Interactive iterations among these variables are implemented with a message-passing algorithm over a factor graph. Simulation results show that using learned information outside a neighborhood jointly with distributed link-scheduling reduces the outage probability close to zero even for a small neighborhood.
Distributed Preemption Decisions: Probabilistic Graphical Model, Algorithm and Near-Optimality
Jan 07, 2009



Cooperative decision making is a vision of future network management and control. Distributed connection preemption is an important example where nodes can make intelligent decisions on allocating resources and controlling traffic flows for multi-class service networks. A challenge is that nodal decisions are spatially dependent as traffic flows trespass multiple nodes in a network. Hence the performance-complexity trade-off becomes important, i.e., how accurate decisions are versus how much information is exchanged among nodes. Connection preemption is known to be NP-complete. Centralized preemption is optimal but computationally intractable. Decentralized preemption is computationally efficient but may result in a poor performance. This work investigates distributed preemption where nodes decide whether and which flows to preempt using only local information exchange with neighbors. We develop, based on the probabilistic graphical models, a near-optimal distributed algorithm. The algorithm is used by each node to make collectively near-optimal preemption decisions. We study trade-offs between near-optimal performance and complexity that corresponds to the amount of information-exchange of the distributed algorithm. The algorithm is validated by both analysis and simulation.