 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGradients: When Markets Meet Fine-tuning -- A Distributed Approach to Model Optimisation
Jun 09, 2025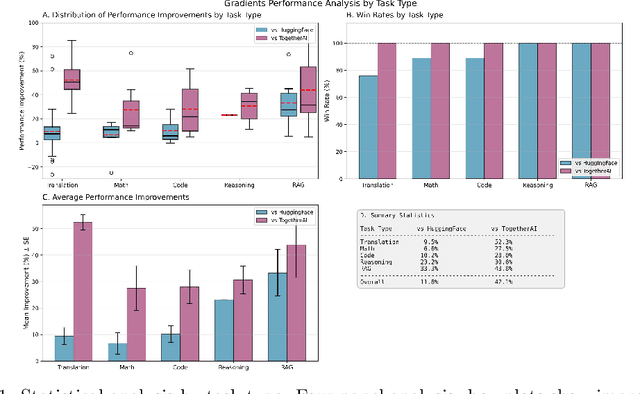
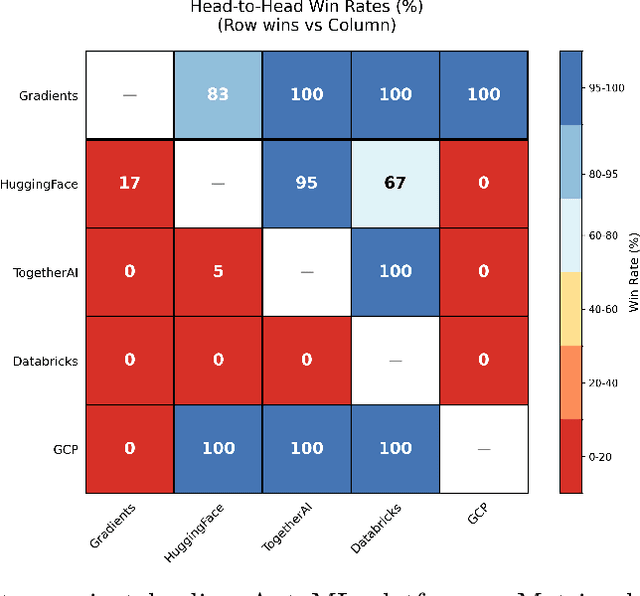
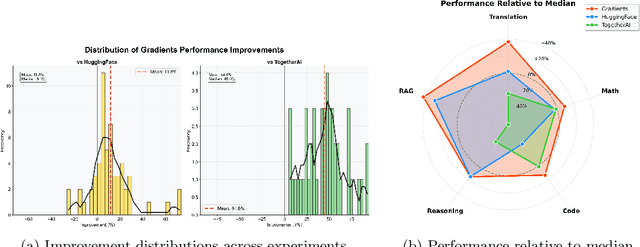
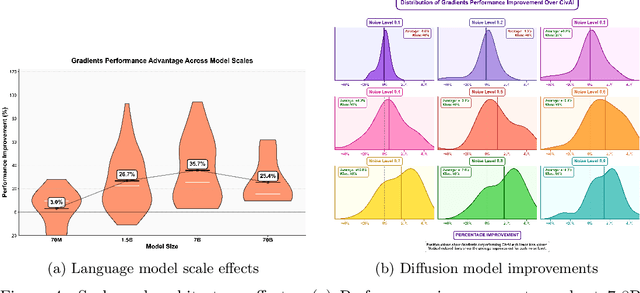
Foundation model fine-tuning faces a fundamental challenge: existing AutoML platforms rely on single optimisation strategies that explore only a fraction of viable hyperparameter configurations. In this white paper, We introduce Gradients, a decentralised AutoML platform that transforms hyperparameter optimisation into a competitive marketplace where independent miners compete to discover optimal configurations. Economic incentives align individual exploration with collective optimisation goals, driving systematic investigation of hyperparameter regions that centralised methods miss. We evaluate our approach across 180 controlled experiments spanning diverse model architectures (70M to 70B parameters) and task types. Gradients achieves an 82.8\% win rate against HuggingFace AutoTrain and 100\% against TogetherAI, Databricks, and Google Cloud, with mean improvements of 11.8\% and 42.1\% respectively. Complex reasoning and retrieval tasks show particularly strong gains of 30-40\%, whilst diffusion models achieve 23.4\% improvements for person-specific generation. These results demonstrate that competitive, economically-driven approaches can systematically discover superior configurations that centralised AutoML consistently miss.
Probabilistic Weight Fixing: Large-scale training of neural network weight uncertainties for quantization
Sep 26, 2023


Weight-sharing quantization has emerged as a technique to reduce energy expenditure during inference in large neural networks by constraining their weights to a limited set of values. However, existing methods for weight-sharing quantization often make assumptions about the treatment of weights based on value alone that neglect the unique role weight position plays. This paper proposes a probabilistic framework based on Bayesian neural networks (BNNs) and a variational relaxation to identify which weights can be moved to which cluster centre and to what degree based on their individual position-specific learned uncertainty distributions. We introduce a new initialisation setting and a regularisation term which allow for the training of BNNs under complex dataset-model combinations. By leveraging the flexibility of weight values captured through a probability distribution, we enhance noise resilience and downstream compressibility. Our iterative clustering procedure demonstrates superior compressibility and higher accuracy compared to state-of-the-art methods on both ResNet models and the more complex transformer-based architectures. In particular, our method outperforms the state-of-the-art quantization method top-1 accuracy by 1.6% on ImageNet using DeiT-Tiny, with its 5 million+ weights now represented by only 296 unique values.
Weight Fixing Networks
Oct 24, 2022



Modern iterations of deep learning models contain millions (billions) of unique parameters, each represented by a b-bit number. Popular attempts at compressing neural networks (such as pruning and quantisation) have shown that many of the parameters are superfluous, which we can remove (pruning) or express with less than b-bits (quantisation) without hindering performance. Here we look to go much further in minimising the information content of networks. Rather than a channel or layer-wise encoding, we look to lossless whole-network quantisation to minimise the entropy and number of unique parameters in a network. We propose a new method, which we call Weight Fixing Networks (WFN) that we design to realise four model outcome objectives: i) very few unique weights, ii) low-entropy weight encodings, iii) unique weight values which are amenable to energy-saving versions of hardware multiplication, and iv) lossless task-performance. Some of these goals are conflicting. To best balance these conflicts, we combine a few novel (and some well-trodden) tricks; a novel regularisation term, (i, ii) a view of clustering cost as relative distance change (i, ii, iv), and a focus on whole-network re-use of weights (i, iii). Our Imagenet experiments demonstrate lossless compression using 56x fewer unique weights and a 1.9x lower weight-space entropy than SOTA quantisation approaches.