 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSensor Adaptation for Improved Semantic Segmentation of Overhead Imagery
Nov 20, 2018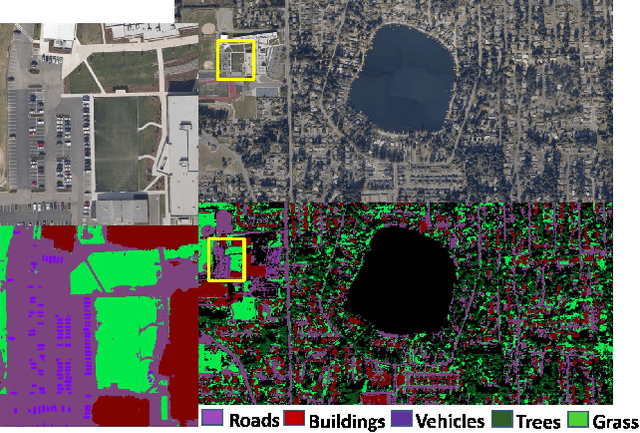
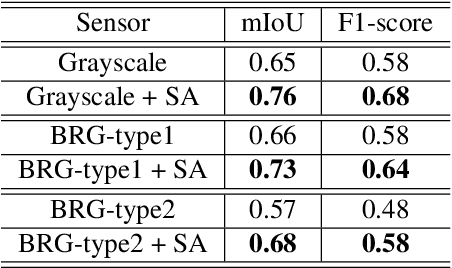
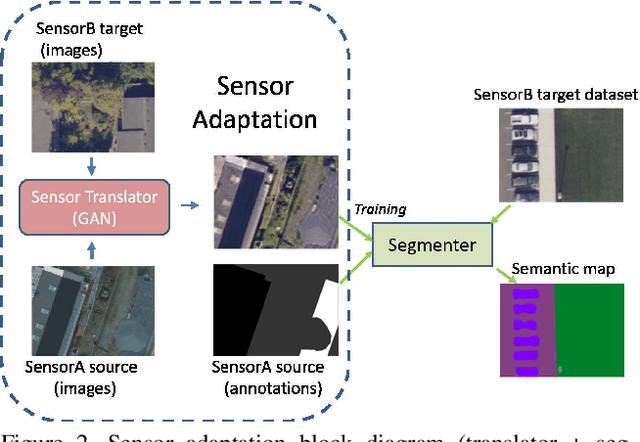
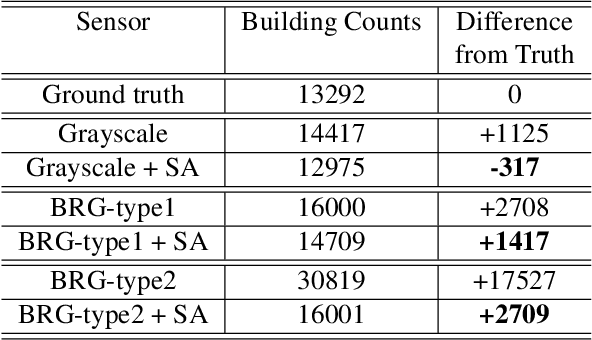
Semantic segmentation is a powerful method to facilitate visual scene understanding. Each pixel is assigned a label according to a pre-defined list of object classes and semantic entities. This becomes very useful as a means to summarize large scale overhead imagery. In this paper we present our work on semantic segmentation with applications to overhead imagery. We propose an algorithm that builds and extends upon the DeepLab framework to be able to refine and resolve small objects (relative to the image size) such as vehicles. We have also investigated sensor adaptation as a means to augment available training data to be able to reduce some of the shortcomings of neural networks when deployed in new environments and to new sensors. We report results on several datasets and compare performance with other state-of-the-art architectures.
Improved Image Segmentation via Cost Minimization of Multiple Hypotheses
Jan 31, 2018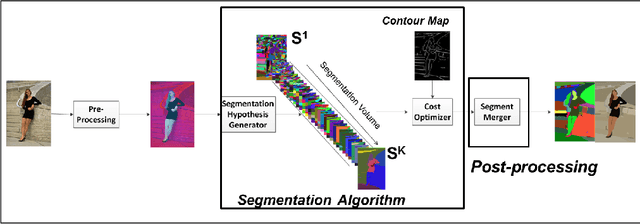
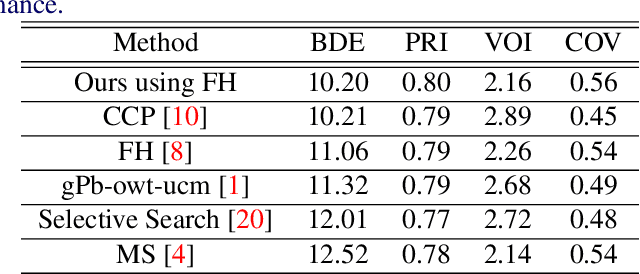
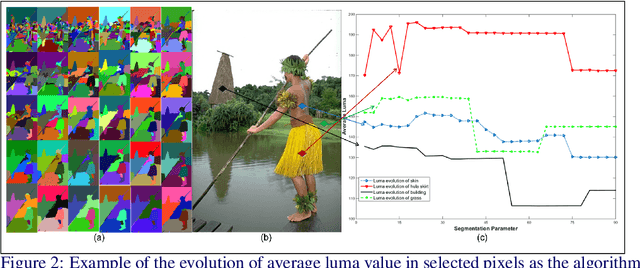
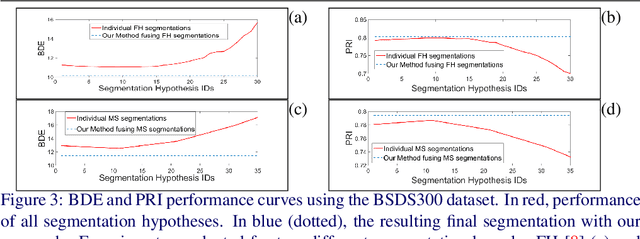
Image segmentation is an important component of many image understanding systems. It aims to group pixels in a spatially and perceptually coherent manner. Typically, these algorithms have a collection of parameters that control the degree of over-segmentation produced. It still remains a challenge to properly select such parameters for human-like perceptual grouping. In this work, we exploit the diversity of segments produced by different choices of parameters. We scan the segmentation parameter space and generate a collection of image segmentation hypotheses (from highly over-segmented to under-segmented). These are fed into a cost minimization framework that produces the final segmentation by selecting segments that: (1) better describe the natural contours of the image, and (2) are more stable and persistent among all the segmentation hypotheses. We compare our algorithm's performance with state-of-the-art algorithms, showing that we can achieve improved results. We also show that our framework is robust to the choice of segmentation kernel that produces the initial set of hypotheses.
Super-Resolution for Overhead Imagery Using DenseNets and Adversarial Learning
Nov 28, 2017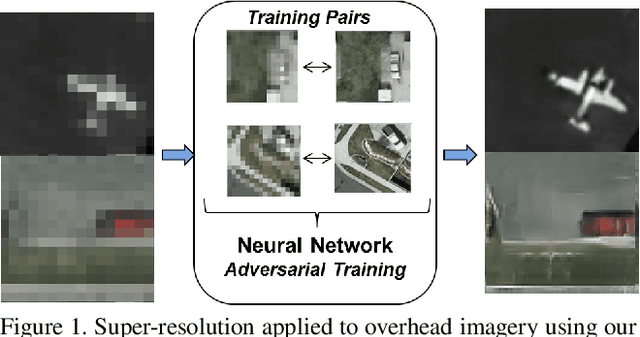

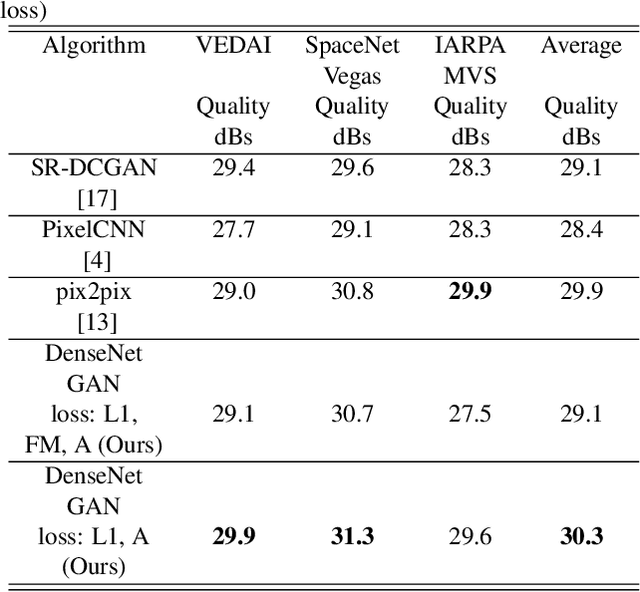
Recent advances in Generative Adversarial Learning allow for new modalities of image super-resolution by learning low to high resolution mappings. In this paper we present our work using Generative Adversarial Networks (GANs) with applications to overhead and satellite imagery. We have experimented with several state-of-the-art architectures. We propose a GAN-based architecture using densely connected convolutional neural networks (DenseNets) to be able to super-resolve overhead imagery with a factor of up to 8x. We have also investigated resolution limits of these networks. We report results on several publicly available datasets, including SpaceNet data and IARPA Multi-View Stereo Challenge, and compare performance with other state-of-the-art architectures.