 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimulation-based Scenario Generation for Robust Hybrid AI for Autonomy
Sep 10, 2024



Application of Unmanned Aerial Vehicles (UAVs) in search and rescue, emergency management, and law enforcement has gained traction with the advent of low-cost platforms and sensor payloads. The emergence of hybrid neural and symbolic AI approaches for complex reasoning is expected to further push the boundaries of these applications with decreasing levels of human intervention. However, current UAV simulation environments lack semantic context suited to this hybrid approach. To address this gap, HAMERITT (Hybrid Ai Mission Environment for RapId Training and Testing) provides a simulation-based autonomy software framework that supports the training, testing and assurance of neuro-symbolic algorithms for autonomous maneuver and perception reasoning. HAMERITT includes scenario generation capabilities that offer mission-relevant contextual symbolic information in addition to raw sensor data. Scenarios include symbolic descriptions for entities of interest and their relations to scene elements, as well as spatial-temporal constraints in the form of time-bounded areas of interest with prior probabilities and restricted zones within those areas. HAMERITT also features support for training distinct algorithm threads for maneuver vs. perception within an end-to-end mission run. Future work includes improving scenario realism and scaling symbolic context generation through automated workflow.
Multi-Object Tracking with Deep Learning Ensemble for Unmanned Aerial System Applications
Oct 05, 2021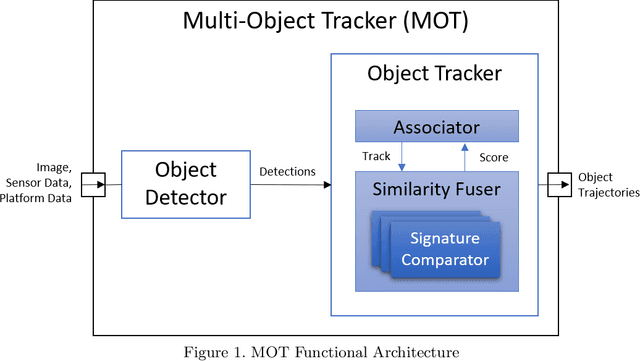

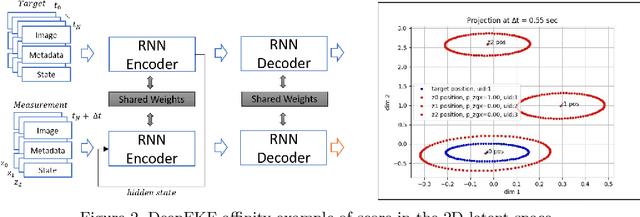
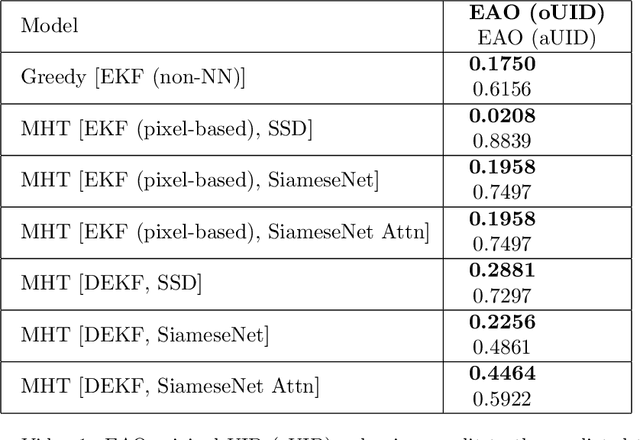
Multi-object tracking (MOT) is a crucial component of situational awareness in military defense applications. With the growing use of unmanned aerial systems (UASs), MOT methods for aerial surveillance is in high demand. Application of MOT in UAS presents specific challenges such as moving sensor, changing zoom levels, dynamic background, illumination changes, obscurations and small objects. In this work, we present a robust object tracking architecture aimed to accommodate for the noise in real-time situations. We propose a kinematic prediction model, called Deep Extended Kalman Filter (DeepEKF), in which a sequence-to-sequence architecture is used to predict entity trajectories in latent space. DeepEKF utilizes a learned image embedding along with an attention mechanism trained to weight the importance of areas in an image to predict future states. For the visual scoring, we experiment with different similarity measures to calculate distance based on entity appearances, including a convolutional neural network (CNN) encoder, pre-trained using Siamese networks. In initial evaluation experiments, we show that our method, combining scoring structure of the kinematic and visual models within a MHT framework, has improved performance especially in edge cases where entity motion is unpredictable, or the data presents frames with significant gaps.