 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReducing Memory Requirements for the IPU using Butterfly Factorizations
Sep 16, 2023


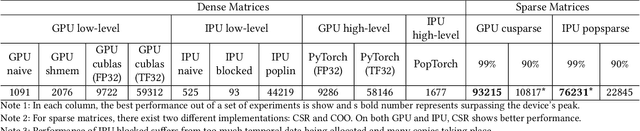
High Performance Computing (HPC) benefits from different improvements during last decades, specially in terms of hardware platforms to provide more processing power while maintaining the power consumption at a reasonable level. The Intelligence Processing Unit (IPU) is a new type of massively parallel processor, designed to speedup parallel computations with huge number of processing cores and on-chip memory components connected with high-speed fabrics. IPUs mainly target machine learning applications, however, due to the architectural differences between GPUs and IPUs, especially significantly less memory capacity on an IPU, methods for reducing model size by sparsification have to be considered. Butterfly factorizations are well-known replacements for fully-connected and convolutional layers. In this paper, we examine how butterfly structures can be implemented on an IPU and study their behavior and performance compared to a GPU. Experimental results indicate that these methods can provide 98.5% compression ratio to decrease the immense need for memory, the IPU implementation can benefit from 1.3x and 1.6x performance improvement for butterfly and pixelated butterfly, respectively. We also reach to 1.62x training time speedup on a real-word dataset such as CIFAR10.