 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFotheidil: an Automatic Transcription System for the Irish Language
Dec 31, 2024



This paper sets out the first web-based transcription system for the Irish language - Fotheidil, a system that utilises speech-related AI technologies as part of the ABAIR initiative. The system includes both off-the-shelf pre-trained voice activity detection and speaker diarisation models and models trained specifically for Irish automatic speech recognition and capitalisation and punctuation restoration. Semi-supervised learning is explored to improve the acoustic model of a modular TDNN-HMM ASR system, yielding substantial improvements for out-of-domain test sets and dialects that are underrepresented in the supervised training set. A novel approach to capitalisation and punctuation restoration involving sequence-to-sequence models is compared with the conventional approach using a classification model. Experimental results show here also substantial improvements in performance. The system will be made freely available for public use, and represents an important resource to researchers and others who transcribe Irish language materials. Human-corrected transcriptions will be collected and included in the training dataset as the system is used, which should lead to incremental improvements to the ASR model in a cyclical, community-driven fashion.
Low-resource speech recognition and dialect identification of Irish in a multi-task framework
May 02, 2024This paper explores the use of Hybrid CTC/Attention encoder-decoder models trained with Intermediate CTC (InterCTC) for Irish (Gaelic) low-resource speech recognition (ASR) and dialect identification (DID). Results are compared to the current best performing models trained for ASR (TDNN-HMM) and DID (ECAPA-TDNN). An optimal InterCTC setting is initially established using a Conformer encoder. This setting is then used to train a model with an E-branchformer encoder and the performance of both architectures are compared. A multi-task fine-tuning approach is adopted for language model (LM) shallow fusion. The experiments yielded an improvement in DID accuracy of 10.8% relative to a baseline ECAPA-TDNN, and WER performance approaching the TDNN-HMM model. This multi-task approach emerges as a promising strategy for Irish low-resource ASR and DID.
Towards dialect-inclusive recognition in a low-resource language: are balanced corpora the answer?
Jul 14, 2023ASR systems are generally built for the spoken 'standard', and their performance declines for non-standard dialects/varieties. This is a problem for a language like Irish, where there is no single spoken standard, but rather three major dialects: Ulster (Ul), Connacht (Co) and Munster (Mu). As a diagnostic to quantify the effect of the speaker's dialect on recognition performance, 12 ASR systems were trained, firstly using baseline dialect-balanced training corpora, and then using modified versions of the baseline corpora, where dialect-specific materials were either subtracted or added. Results indicate that dialect-balanced corpora do not yield a similar performance across the dialects: the Ul dialect consistently underperforms, whereas Mu yields lowest WERs. There is a close relationship between Co and Mu dialects, but one that is not symmetrical. These results will guide future corpus collection and system building strategies to optimise for cross-dialect performance equity.
Towards spoken dialect identification of Irish
Jul 14, 2023The Irish language is rich in its diversity of dialects and accents. This compounds the difficulty of creating a speech recognition system for the low-resource language, as such a system must contend with a high degree of variability with limited corpora. A recent study investigating dialect bias in Irish ASR found that balanced training corpora gave rise to unequal dialect performance, with performance for the Ulster dialect being consistently worse than for the Connacht or Munster dialects. Motivated by this, the present experiments investigate spoken dialect identification of Irish, with a view to incorporating such a system into the speech recognition pipeline. Two acoustic classification models are tested, XLS-R and ECAPA-TDNN, in conjunction with a text-based classifier using a pretrained Irish-language BERT model. The ECAPA-TDNN, particularly a model pretrained for language identification on the VoxLingua107 dataset, performed best overall, with an accuracy of 73%. This was further improved to 76% by fusing the model's outputs with the text-based model. The Ulster dialect was most accurately identified, with an accuracy of 94%, however the model struggled to disambiguate between the Connacht and Munster dialects, suggesting a more nuanced approach may be necessary to robustly distinguish between the dialects of Irish.
Data-driven Detection and Analysis of the Patterns of Creaky Voice
May 31, 2020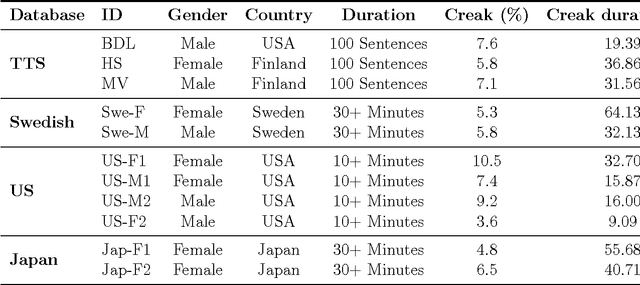

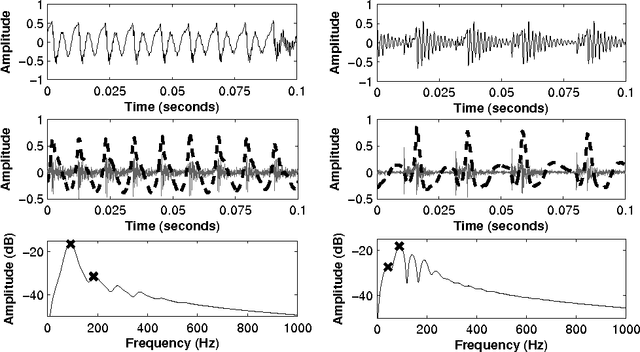
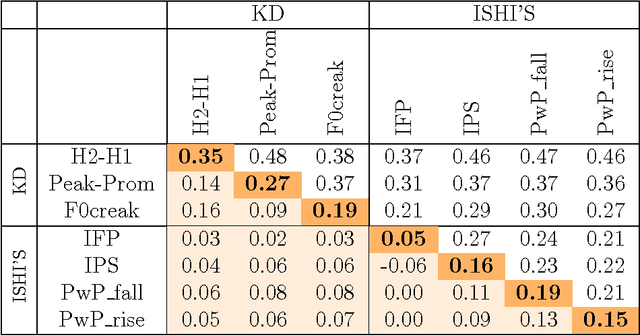
This paper investigates the temporal excitation patterns of creaky voice. Creaky voice is a voice quality frequently used as a phrase-boundary marker, but also as a means of portraying attitude, affective states and even social status. Consequently, the automatic detection and modelling of creaky voice may have implications for speech technology applications. The acoustic characteristics of creaky voice are, however, rather distinct from modal phonation. Further, several acoustic patterns can bring about the perception of creaky voice, thereby complicating the strategies used for its automatic detection, analysis and modelling. The present study is carried out using a variety of languages, speakers, and on both read and conversational data and involves a mutual information-based assessment of the various acoustic features proposed in the literature for detecting creaky voice. These features are then exploited in classification experiments where we achieve an appreciable improvement in detection accuracy compared to the state of the art. Both experiments clearly highlight the presence of several creaky patterns. A subsequent qualitative and quantitative analysis of the identified patterns is provided, which reveals a considerable speaker-dependent variability in the usage of these creaky patterns. We also investigate how creaky voice detection systems perform across creaky patterns.