 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Content Adaptive Learnable Time-Frequency Representation For Audio Signal Processing
Mar 18, 2023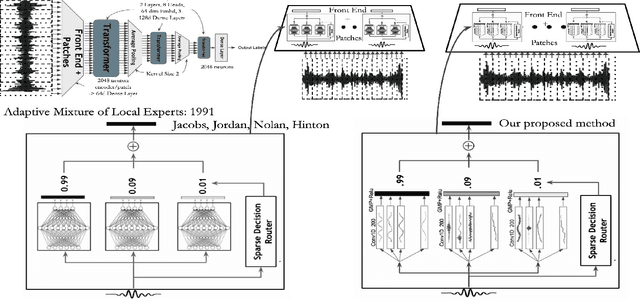


We propose a learnable content adaptive front end for audio signal processing. Before the modern advent of deep learning, we used fixed representation non-learnable front-ends like spectrogram or mel-spectrogram with/without neural architectures. With convolutional architectures supporting various applications such as ASR and acoustic scene understanding, a shift to a learnable front ends occurred in which both the type of basis functions and the weight were learned from scratch and optimized for the particular task of interest. With the shift to transformer-based architectures with no convolutional blocks present, a linear layer projects small waveform patches onto a small latent dimension before feeding them to a transformer architecture. In this work, we propose a way of computing a content-adaptive learnable time-frequency representation. We pass each audio signal through a bank of convolutional filters, each giving a fixed-dimensional vector. It is akin to learning a bank of finite impulse-response filterbanks and passing the input signal through the optimum filter bank depending on the content of the input signal. A content-adaptive learnable time-frequency representation may be more broadly applicable, beyond the experiments in this paper.
One-Shot Acoustic Matching Of Audio Signals -- Learning to Hear Music In Any Room/ Concert Hall
Oct 31, 2022
The acoustic space in which a sound is created and heard plays an essential role in how that sound is perceived by affording a unique sense of \textit{presence}. Every sound we hear results from successive convolution operations intrinsic to the sound source and external factors such as microphone characteristics and room impulse responses. Typically, researchers use an excitation such as a pistol shot or balloon pop as an impulse signal with which an auralization can be created. The room "impulse" responses convolved with the signal of interest can transform the input sound into the sound played in the acoustic space of interest. Here we propose a novel architecture that can transform a sound of interest into any other acoustic space(room or hall) of interest by using arbitrary audio recorded as a proxy for a balloon pop. The architecture is grounded in simple signal processing ideas to learn residual signals from a learned acoustic signature and the input signal. Our framework allows a neural network to adjust gains of every point in the time-frequency representation, giving sound qualitative and quantitative results.
A Generative Model for Raw Audio Using Transformer Architectures
Jul 08, 2021

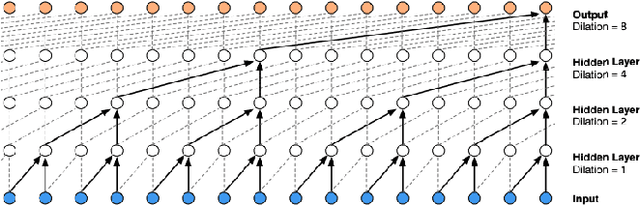
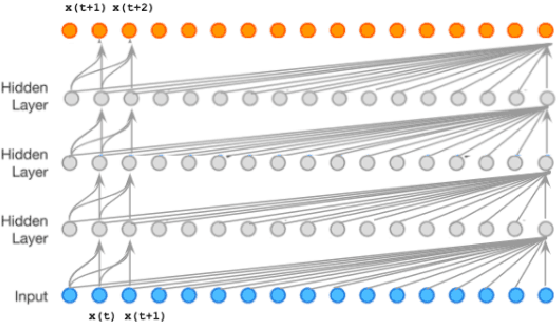
This paper proposes a novel way of doing audio synthesis at the waveform level using Transformer architectures. We propose a deep neural network for generating waveforms, similar to wavenet. This is fully probabilistic, auto-regressive, and causal, i.e. each sample generated depends only on the previously observed samples. Our approach outperforms a widely used wavenet architecture by up to 9% on a similar dataset for predicting the next step. Using the attention mechanism, we enable the architecture to learn which audio samples are important for the prediction of the future sample. We show how causal transformer generative models can be used for raw waveform synthesis. We also show that this performance can be improved by another 2% by conditioning samples over a wider context. The flexibility of the current model to synthesize audio from latent representations suggests a large number of potential applications. The novel approach of using generative transformer architectures for raw audio synthesis is, however, still far away from generating any meaningful music, without using latent codes/meta-data to aid the generation process.
A Deep Learning Approach for Low-Latency Packet Loss Concealment of Audio Signals in Networked Music Performance Applications
Jul 14, 2020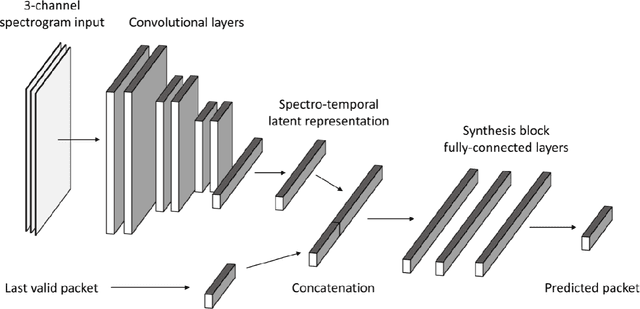
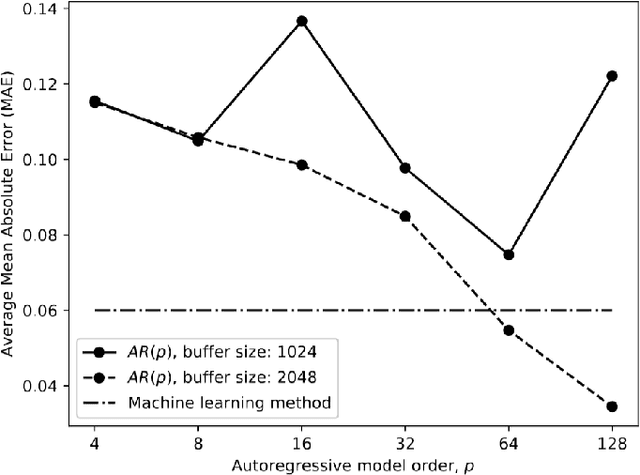
Networked Music Performance (NMP) is envisioned as a potential game changer among Internet applications: it aims at revolutionizing the traditional concept of musical interaction by enabling remote musicians to interact and perform together through a telecommunication network. Ensuring realistic conditions for music performance, however, constitutes a significant engineering challenge due to extremely strict requirements in terms of audio quality and, most importantly, network delay. To minimize the end-to-end delay experienced by the musicians, typical implementations of NMP applications use un-compressed, bidirectional audio streams and leverage UDP as transport protocol. Being connection less and unreliable,audio packets transmitted via UDP which become lost in transit are not re-transmitted and thus cause glitches in the receiver audio playout. This article describes a technique for predicting lost packet content in real-time using a deep learning approach. The ability of concealing errors in real time can help mitigate audio impairments caused by packet losses, thus improving the quality of audio playout in real-world scenarios.
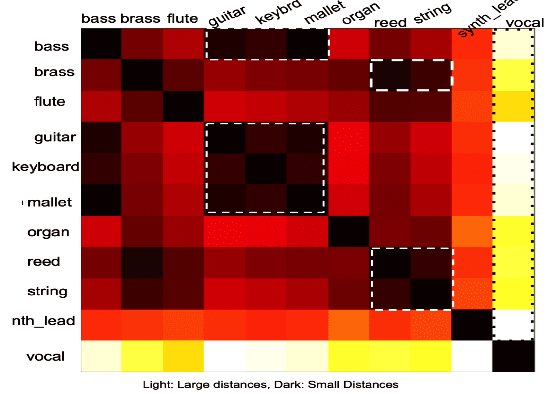
Neuralogram: A Deep Neural Network Based Representation for Audio Signals
Apr 10, 2019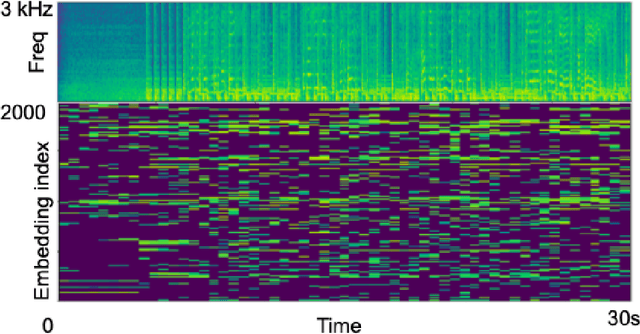
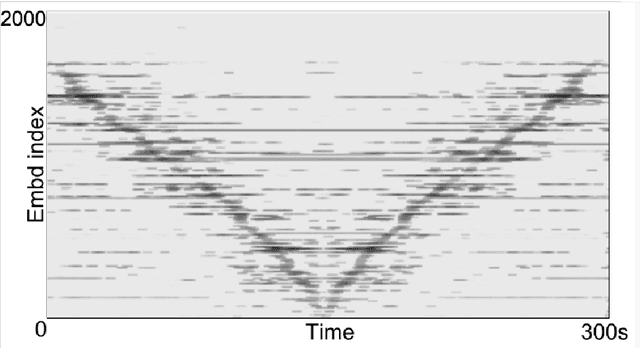

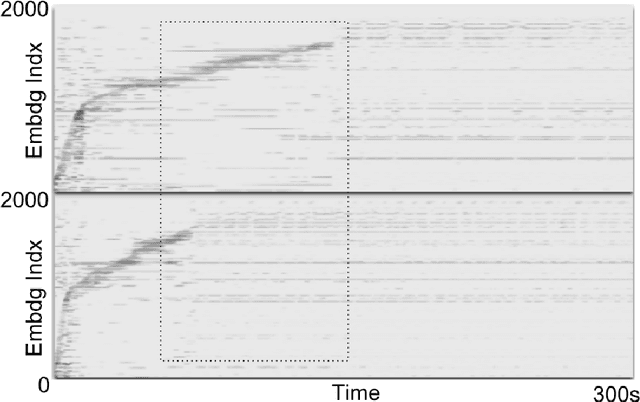
We propose the Neuralogram -- a deep neural network based representation for understanding audio signals which, as the name suggests, transforms an audio signal to a dense, compact representation based upon embeddings learned via a neural architecture. Through a series of probing signals, we show how our representation can encapsulate pitch, timbre and rhythm-based information, and other attributes. This representation suggests a method for revealing meaningful relationships in arbitrarily long audio signals that are not readily represented by existing algorithms. This has the potential for numerous applications in audio understanding, music recommendation, meta-data extraction to name a few.