 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Latent Emotion Network for Multi-Task Learning
Apr 18, 2021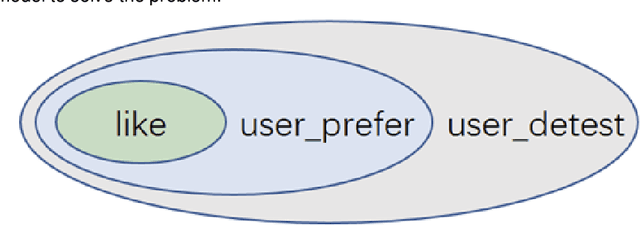
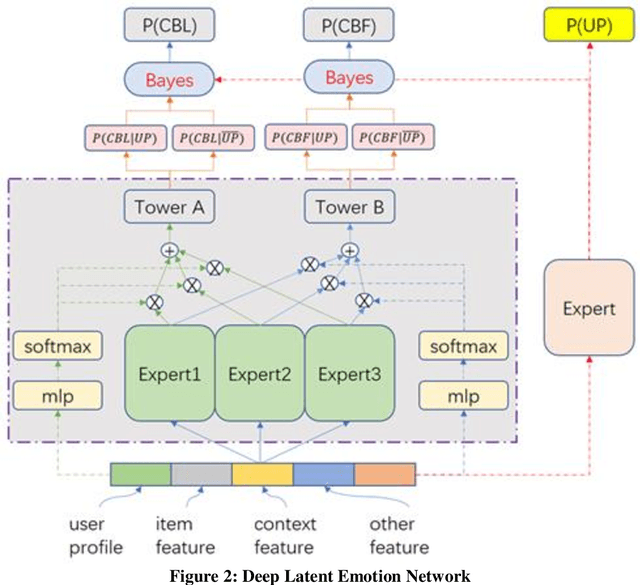

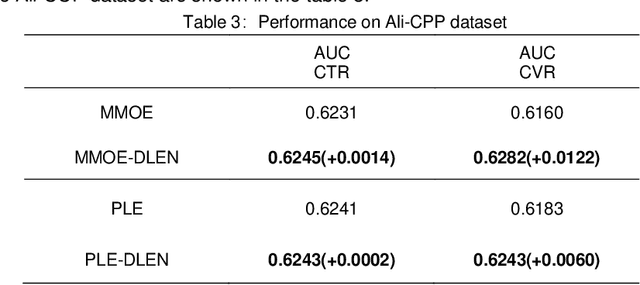
Feed recommendation models are widely adopted by numerous feed platforms to encourage users to explore the contents they are interested in. However, most of the current research simply focus on targeting user's preference and lack in-depth study of avoiding objectionable contents to be frequently recommended, which is a common reason that let user detest. To address this issue, we propose a Deep Latent Emotion Network (DLEN) model to extract latent probability of a user preferring a feed by modeling multiple targets with semi-supervised learning. With this method, the conflicts of different targets are successfully reduced in the training phase, which improves the training accuracy of each target effectively. Besides, by adding this latent state of user emotion to multi-target fusion, the model is capable of decreasing the probability to recommend objectionable contents to improve user retention and stay time during online testing phase. DLEN is deployed on a real-world multi-task feed recommendation scenario of Tencent QQ-Small-World with a dataset containing over a billion samples, and it exhibits a significant performance advantage over the SOTA MTL model in offline evaluation, together with a considerable increase by 3.02% in view-count and 2.63% in user stay-time in production. Complementary offline experiments of DLEN model on a public dataset also repeat improvements in various scenarios. At present, DLEN model has been successfully deployed in Tencent's feed recommendation system.
An Improved multi-objective genetic algorithm based on orthogonal design and adaptive clustering pruning strategy
Jan 03, 2019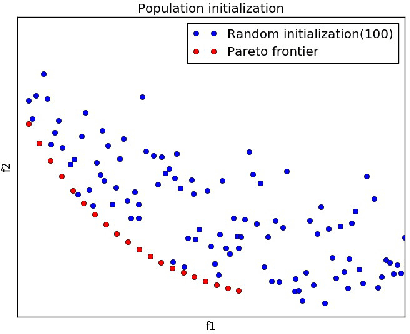
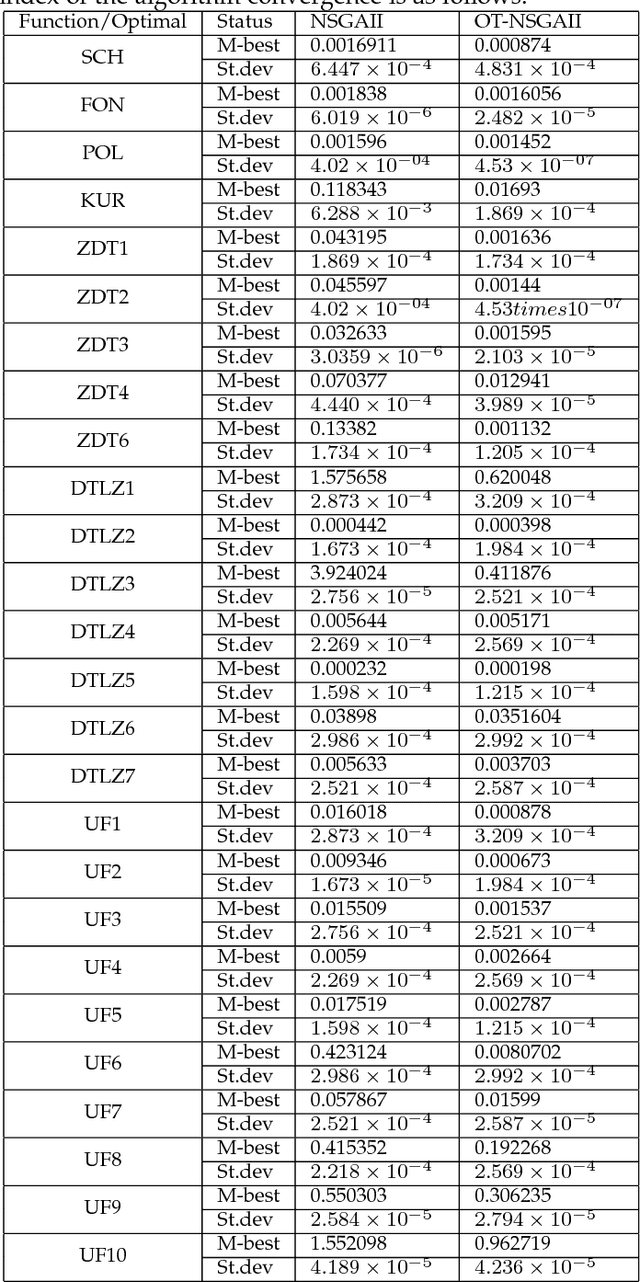
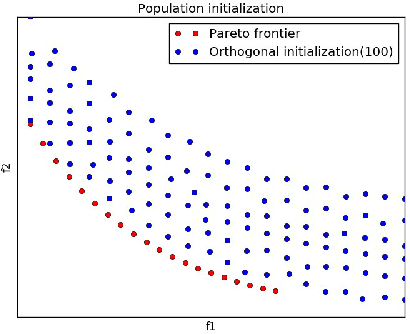
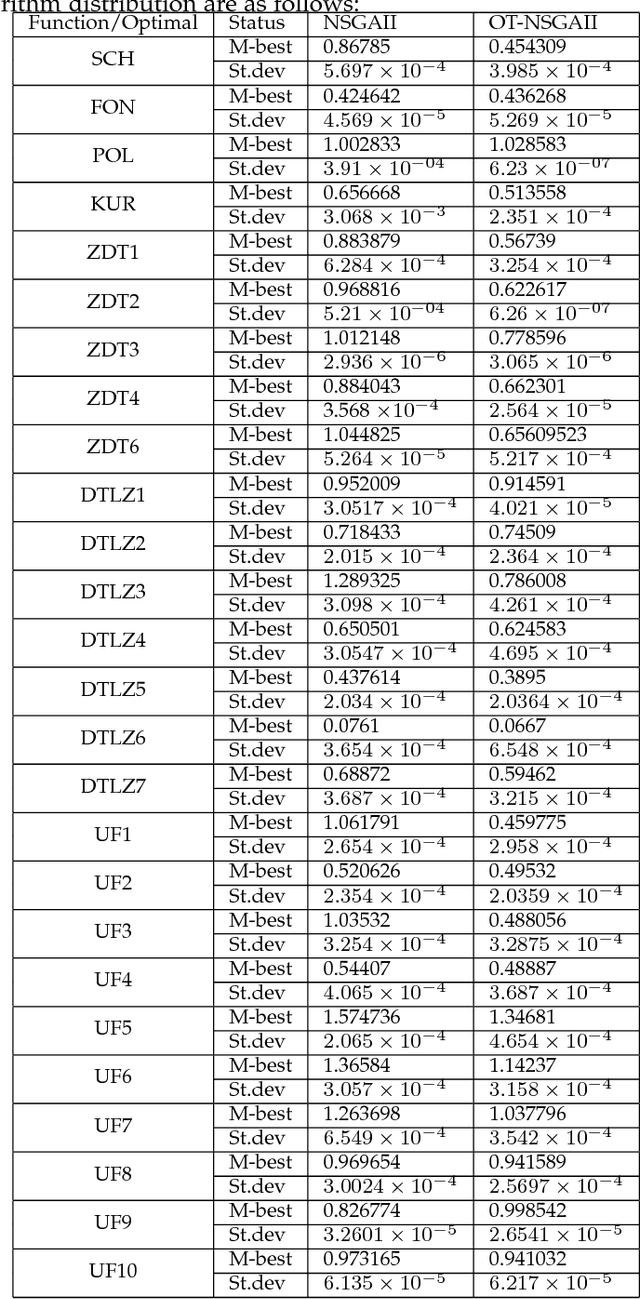
Two important characteristics of multi-objective evolutionary algorithms are distribution and convergency. As a classic multi-objective genetic algorithm, NSGA-II is widely used in multi-objective optimization fields. However, in NSGA-II, the random population initialization and the strategy of population maintenance based on distance cannot maintain the distribution or convergency of the population well. To dispose these two deficiencies, this paper proposes an improved algorithm, OTNSGA-II II, which has a better performance on distribution and convergency. The new algorithm adopts orthogonal experiment, which selects individuals in manner of a new discontinuing non-dominated sorting and crowding distance, to produce the initial population. And a new pruning strategy based on clustering is proposed to self-adaptively prunes individuals with similar features and poor performance in non-dominated sorting and crowding distance, or to individuals are far away from the Pareto Front according to the degree of intra-class aggregation of clustering results. The new pruning strategy makes population to converge to the Pareto Front more easily and maintain the distribution of population. OTNSGA-II and NSGA-II are compared on various types of test functions to verify the improvement of OTNSGA-II in terms of distribution and convergency.