 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing High-Dimensional Oblique Splits
Mar 18, 2025Orthogonal-split trees perform well, but evidence suggests oblique splits can enhance their performance. This paper explores optimizing high-dimensional $s$-sparse oblique splits from $\{(\vec{w}, \vec{w}^{\top}\boldsymbol{X}_{i}) : i\in \{1,\dots, n\}, \vec{w} \in \mathbb{R}^p, \| \vec{w} \|_{2} = 1, \| \vec{w} \|_{0} \leq s \}$ for growing oblique trees, where $ s $ is a user-defined sparsity parameter. We establish a connection between SID convergence and $s_0$-sparse oblique splits with $s_0\ge 1$, showing that the SID function class expands as $s_0$ increases, enabling the capture of more complex data-generating functions such as the $s_0$-dimensional XOR function. Thus, $s_0$ represents the unknown potential complexity of the underlying data-generating function. Learning these complex functions requires an $s$-sparse oblique tree with $s \geq s_0$ and greater computational resources. This highlights a trade-off between statistical accuracy, governed by the SID function class size depending on $s_0$, and computational cost. In contrast, previous studies have explored the problem of SID convergence using orthogonal splits with $ s_0 = s = 1 $, where runtime was less critical. Additionally, we introduce a practical framework for oblique trees that integrates optimized oblique splits alongside orthogonal splits into random forests. The proposed approach is assessed through simulations and real-data experiments, comparing its performance against various oblique tree models.
Analyze Additive and Interaction Effects via Collaborative Trees
May 19, 2024We present Collaborative Trees, a novel tree model designed for regression prediction, along with its bagging version, which aims to analyze complex statistical associations between features and uncover potential patterns inherent in the data. We decompose the mean decrease in impurity from the proposed tree model to analyze the additive and interaction effects of features on the response variable. Additionally, we introduce network diagrams to visually depict how each feature contributes additively to the response and how pairs of features contribute interaction effects. Through a detailed demonstration using an embryo growth dataset, we illustrate how the new statistical tools aid data analysis, both visually and numerically. Moreover, we delve into critical aspects of tree modeling, such as prediction performance, inference stability, and bias in feature importance measures, leveraging real datasets and simulation experiments for comprehensive discussions. On the theory side, we show that Collaborative Trees, built upon a ``sum of trees'' approach with our own innovative tree model regularization, exhibit characteristics akin to matching pursuit, under the assumption of high-dimensional independent binary input features (or one-hot feature groups). This newfound link sheds light on the superior capability of our tree model in estimating additive effects of features, a crucial factor for accurate interaction effect estimation.
FACT: High-Dimensional Random Forests Inference
Jul 04, 2022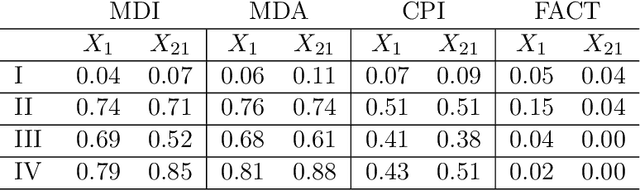
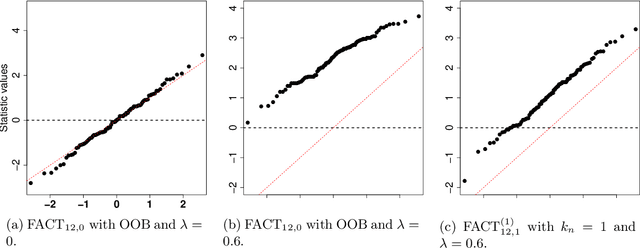
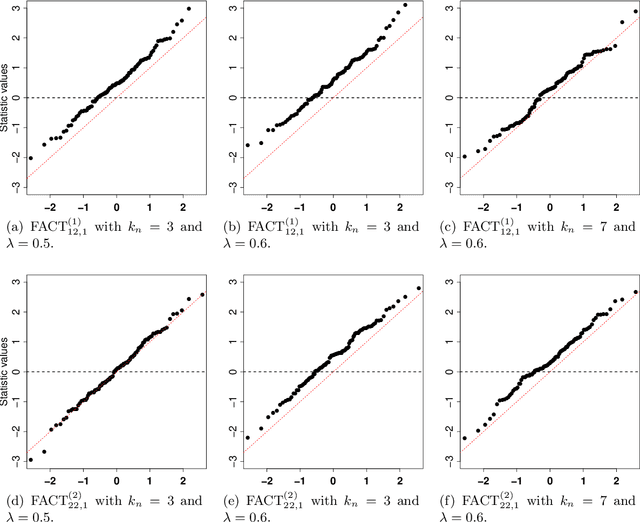

Random forests is one of the most widely used machine learning methods over the past decade thanks to its outstanding empirical performance. Yet, because of its black-box nature, the results by random forests can be hard to interpret in many big data applications. Quantifying the usefulness of individual features in random forests learning can greatly enhance its interpretability. Existing studies have shown that some popularly used feature importance measures for random forests suffer from the bias issue. In addition, there lack comprehensive size and power analyses for most of these existing methods. In this paper, we approach the problem via hypothesis testing, and suggest a framework of the self-normalized feature-residual correlation test (FACT) for evaluating the significance of a given feature in the random forests model with bias-resistance property, where our null hypothesis concerns whether the feature is conditionally independent of the response given all other features. Such an endeavor on random forests inference is empowered by some recent developments on high-dimensional random forests consistency. The vanilla version of our FACT test can suffer from the bias issue in the presence of feature dependency. We exploit the techniques of imbalancing and conditioning for bias correction. We further incorporate the ensemble idea into the FACT statistic through feature transformations for the enhanced power. Under a fairly general high-dimensional nonparametric model setting with dependent features, we formally establish that FACT can provide theoretically justified random forests feature p-values and enjoy appealing power through nonasymptotic analyses. The theoretical results and finite-sample advantages of the newly suggested method are illustrated with several simulation examples and an economic forecasting application in relation to COVID-19.