 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Adversarial Detection without Extra Model: Training Loss Should Change
Aug 07, 2023
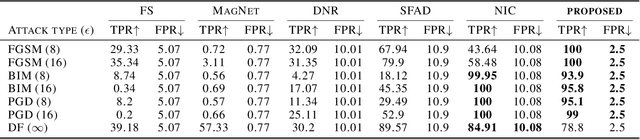
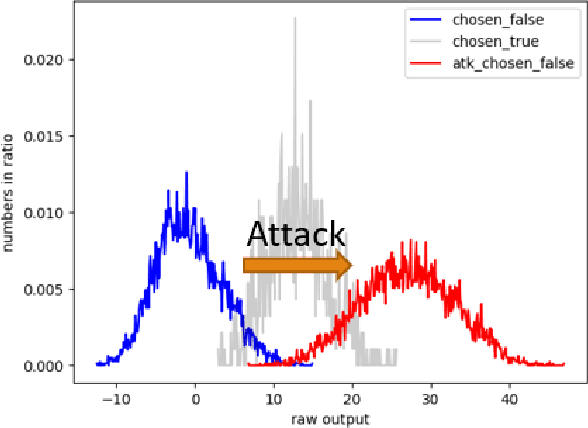
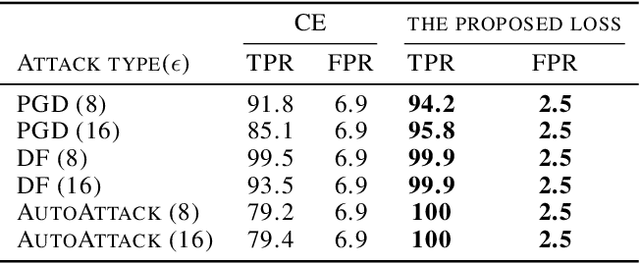
Adversarial robustness poses a critical challenge in the deployment of deep learning models for real-world applications. Traditional approaches to adversarial training and supervised detection rely on prior knowledge of attack types and access to labeled training data, which is often impractical. Existing unsupervised adversarial detection methods identify whether the target model works properly, but they suffer from bad accuracies owing to the use of common cross-entropy training loss, which relies on unnecessary features and strengthens adversarial attacks. We propose new training losses to reduce useless features and the corresponding detection method without prior knowledge of adversarial attacks. The detection rate (true positive rate) against all given white-box attacks is above 93.9% except for attacks without limits (DF($\infty$)), while the false positive rate is barely 2.5%. The proposed method works well in all tested attack types and the false positive rates are even better than the methods good at certain types.