 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistinguishing AI-Generated and Human-Written Text Through Psycholinguistic Analysis
May 03, 2025The increasing sophistication of AI-generated texts highlights the urgent need for accurate and transparent detection tools, especially in educational settings, where verifying authorship is essential. Existing literature has demonstrated that the application of stylometric features with machine learning classifiers can yield excellent results. Building on this foundation, this study proposes a comprehensive framework that integrates stylometric analysis with psycholinguistic theories, offering a clear and interpretable approach to distinguishing between AI-generated and human-written texts. This research specifically maps 31 distinct stylometric features to cognitive processes such as lexical retrieval, discourse planning, cognitive load management, and metacognitive self-monitoring. In doing so, it highlights the unique psycholinguistic patterns found in human writing. Through the intersection of computational linguistics and cognitive science, this framework contributes to the development of reliable tools aimed at preserving academic integrity in the era of generative AI.
StyloAI: Distinguishing AI-Generated Content with Stylometric Analysis
May 16, 2024The emergence of large language models (LLMs) capable of generating realistic texts and images has sparked ethical concerns across various sectors. In response, researchers in academia and industry are actively exploring methods to distinguish AI-generated content from human-authored material. However, a crucial question remains: What are the unique characteristics of AI-generated text? Addressing this gap, this study proposes StyloAI, a data-driven model that uses 31 stylometric features to identify AI-generated texts by applying a Random Forest classifier on two multi-domain datasets. StyloAI achieves accuracy rates of 81% and 98% on the test set of the AuTextification dataset and the Education dataset, respectively. This approach surpasses the performance of existing state-of-the-art models and provides valuable insights into the differences between AI-generated and human-authored texts.
HTMLPhish: Enabling Accurate Phishing Web Page Detection by Applying Deep Learning Techniques on HTML Analysis
Aug 28, 2019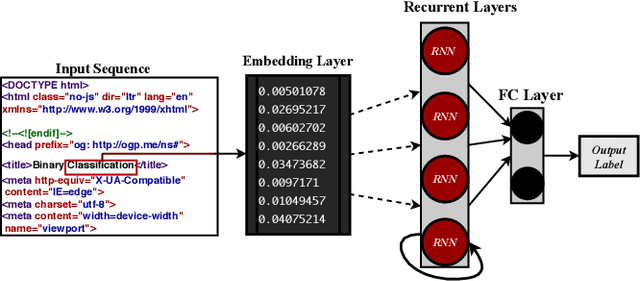
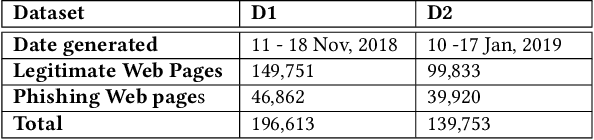
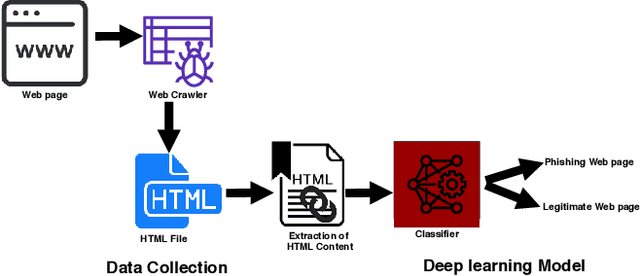
Recently, the development and implementation of phishing attacks require little technical skills and costs. This uprising has led to an ever-growing number of phishing attacks on the World Wide Web daily. Consequently, proactive techniques to fight phishing attacks have become extremely necessary. In this paper, we propose a deep learning model HTMLPhish based on the HTML analysis of a web page for accurate phishing attack detection. By using our proposed HTMLPhish, the experimental results on a dataset of over 300,000 web pages yielded 97.2% accuracy, which significantly outperforms the traditional machine learning methods such as Support Vector Machine, Random Forest and Logistics Regression. We also show the advantage of HTMLPhish in the aspect of the temporal stability and robustness by testing our proposed model on a dataset collected after two months when the model was trained. In addition, HTMLPhish is a completely language-independent and client-side strategy which can, therefore, conduct web page phishing detection regardless of the textual language.