 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAntibody Watch: Text Mining Antibody Specificity from the Literature
Aug 05, 2020
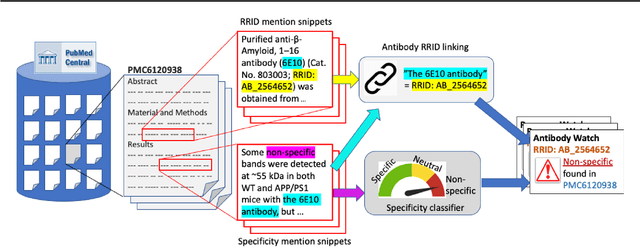
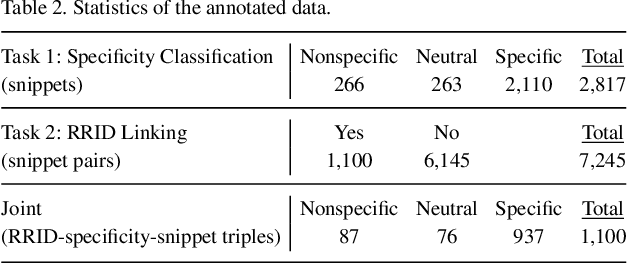
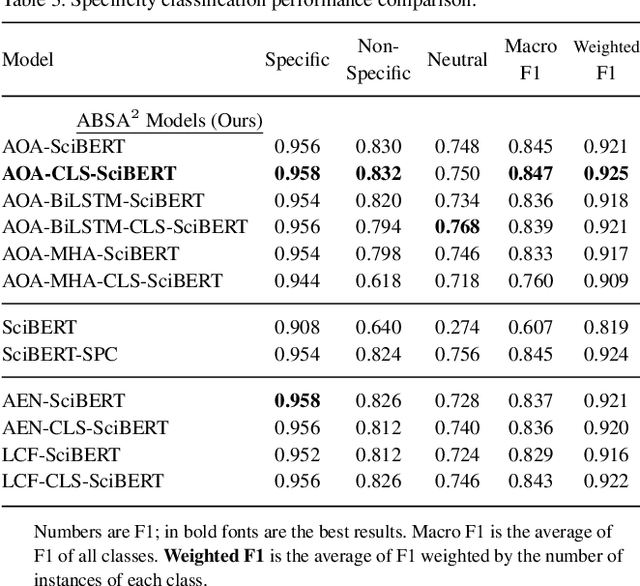
Motivation: Antibodies are widely used reagents to test for expression of proteins. However, they might not always reliably produce results when they do not specifically bind to the target proteins that their providers designed them for, leading to unreliable research results. While many proposals have been developed to deal with the problem of antibody specificity, they may not scale well to deal with the millions of antibodies that are available to researchers. In this study, we investigate the feasibility of automatically generating a report to alert users of problematic antibodies by extracting statements about antibody specificity reported in the literature. Results: Our goal is to construct an "Antibody Watch" knowledge base containing supporting statements of problematic antibodies. We developed a deep neural network system and tested its performance with a corpus of more than two thousand articles that reported uses of antibodies. We divided the problem into two tasks. Given an input article, the first task is to identify snippets about antibody specificity and classify if the snippets report that any antibody exhibits nonspecificity, and thus is problematic. The second task is to link each of these snippets to one or more antibodies mentioned in the snippet. The experimental evaluation shows that our system can accurately perform both classification and linking tasks with weighted F-scores over 0.925 and 0.923, respectively, and 0.914 overall when combined to complete the joint task. We leveraged Research Resource Identifiers (RRID) to precisely identify antibodies linked to the extracted specificity snippets. The result shows that it is feasible to construct a reliable knowledge base about problematic antibodies by text mining.
Short Text Conversation Based on Deep Neural Network and Analysis on Evaluation Measures
Jul 06, 2019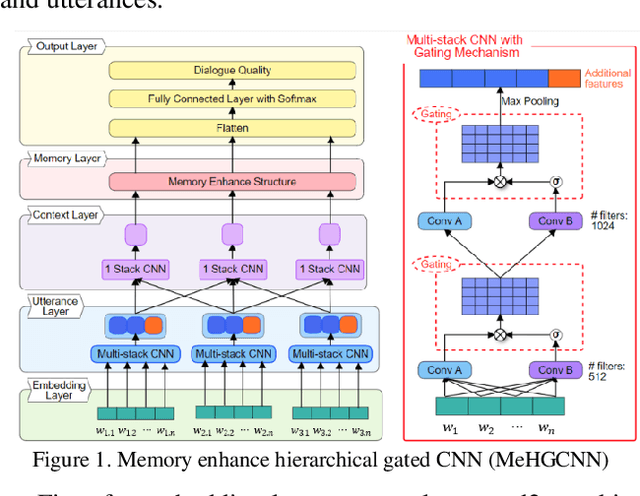
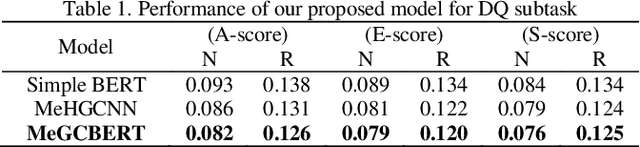

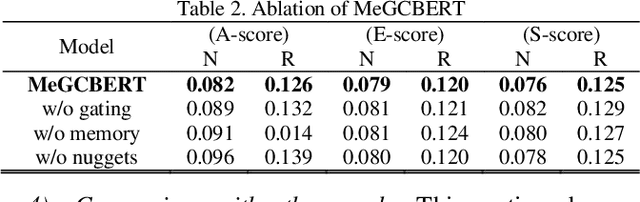
With the development of Natural Language Processing, Automatic question-answering system such as Waston, Siri, Alexa, has become one of the most important NLP applications. Nowadays, enterprises try to build automatic custom service chatbots to save human resources and provide a 24-hour customer service. Evaluation of chatbots currently relied greatly on human annotation which cost a plenty of time. Thus, has initiated a new Short Text Conversation subtask called Dialogue Quality (DQ) and Nugget Detection (ND) which aim to automatically evaluate dialogues generated by chatbots. In this paper, we solve the DQ and ND subtasks by deep neural network. We proposed two models for both DQ and ND subtasks which is constructed by hierarchical structure: embedding layer, utterance layer, context layer and memory layer, to hierarchical learn dialogue representation from word level, sentence level, context level to long range context level. Furthermore, we apply gating and attention mechanism at utterance layer and context layer to improve the performance. We also tried BERT to replace embedding layer and utterance layer as sentence representation. The result shows that BERT produced a better utterance representation than multi-stack CNN for both DQ and ND subtasks and outperform other models proposed by other researches. The evaluation measures are proposed by , that is, NMD, RSNOD for DQ and JSD, RNSS for ND, which is not traditional evaluation measures such as accuracy, precision, recall and f1-score. Thus, we have done a series of experiments by using traditional evaluation measures and analyze the performance and error.