 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Audio-enriched BERT-based Framework for Spoken Multiple-choice Question Answering
May 25, 2020
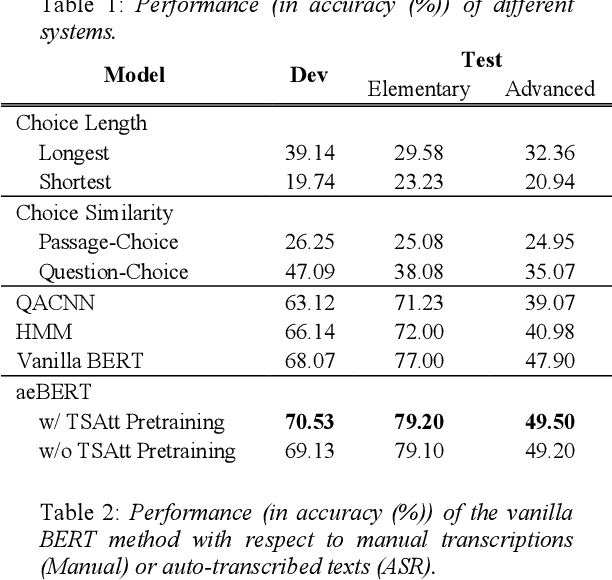

In a spoken multiple-choice question answering (SMCQA) task, given a passage, a question, and multiple choices all in the form of speech, the machine needs to pick the correct choice to answer the question. While the audio could contain useful cues for SMCQA, usually only the auto-transcribed text is utilized in system development. Thanks to the large-scaled pre-trained language representation models, such as the bidirectional encoder representations from transformers (BERT), systems with only auto-transcribed text can still achieve a certain level of performance. However, previous studies have evidenced that acoustic-level statistics can offset text inaccuracies caused by the automatic speech recognition systems or representation inadequacy lurking in word embedding generators, thereby making the SMCQA system robust. Along the line of research, this study concentrates on designing a BERT-based SMCQA framework, which not only inherits the advantages of contextualized language representations learned by BERT, but integrates the complementary acoustic-level information distilled from audio with the text-level information. Consequently, an audio-enriched BERT-based SMCQA framework is proposed. A series of experiments demonstrates remarkable improvements in accuracy over selected baselines and SOTA systems on a published Chinese SMCQA dataset.