 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimal Control of Fluid Restless Multi-armed Bandits: A Machine Learning Approach
Feb 06, 2025



We propose a machine learning approach to the optimal control of fluid restless multi-armed bandits (FRMABs) with state equations that are either affine or quadratic in the state variables. By deriving fundamental properties of FRMAB problems, we design an efficient machine learning based algorithm. Using this algorithm, we solve multiple instances with varying initial states to generate a comprehensive training set. We then learn a state feedback policy using Optimal Classification Trees with hyperplane splits (OCT-H). We test our approach on machine maintenance, epidemic control and fisheries control problems. Our method yields high-quality state feedback policies and achieves a speed-up of up to 26 million times compared to a direct numerical algorithm for fluid problems.
A Machine Learning Approach to Two-Stage Adaptive Robust Optimization
Jul 23, 2023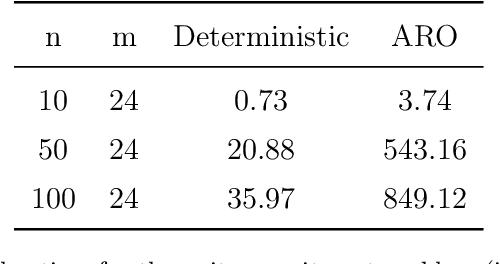
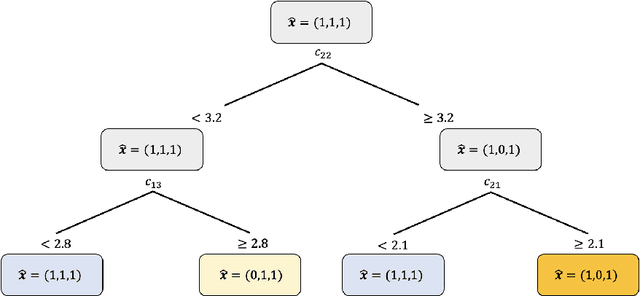
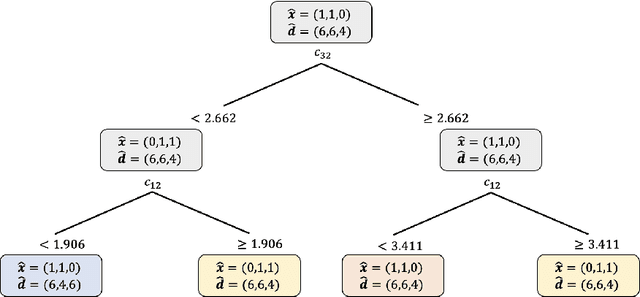
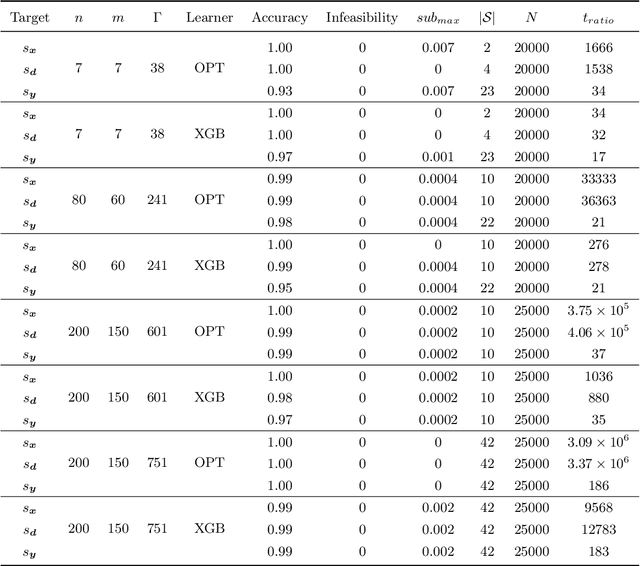
We propose an approach based on machine learning to solve two-stage linear adaptive robust optimization (ARO) problems with binary here-and-now variables and polyhedral uncertainty sets. We encode the optimal here-and-now decisions, the worst-case scenarios associated with the optimal here-and-now decisions, and the optimal wait-and-see decisions into what we denote as the strategy. We solve multiple similar ARO instances in advance using the column and constraint generation algorithm and extract the optimal strategies to generate a training set. We train a machine learning model that predicts high-quality strategies for the here-and-now decisions, the worst-case scenarios associated with the optimal here-and-now decisions, and the wait-and-see decisions. We also introduce an algorithm to reduce the number of different target classes the machine learning algorithm needs to be trained on. We apply the proposed approach to the facility location, the multi-item inventory control and the unit commitment problems. Our approach solves ARO problems drastically faster than the state-of-the-art algorithms with high accuracy.
Optimal Control of Multiclass Fluid Queueing Networks: A Machine Learning Approach
Jul 23, 2023



We propose a machine learning approach to the optimal control of multiclass fluid queueing networks (MFQNETs) that provides explicit and insightful control policies. We prove that a threshold type optimal policy exists for MFQNET control problems, where the threshold curves are hyperplanes passing through the origin. We use Optimal Classification Trees with hyperplane splits (OCT-H) to learn an optimal control policy for MFQNETs. We use numerical solutions of MFQNET control problems as a training set and apply OCT-H to learn explicit control policies. We report experimental results with up to 33 servers and 99 classes that demonstrate that the learned policies achieve 100\% accuracy on the test set. While the offline training of OCT-H can take days in large networks, the online application takes milliseconds.