 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSDSAT: Accelerating LLM Inference through Speculative Decoding with Semantic Adaptive Tokens
Apr 01, 2024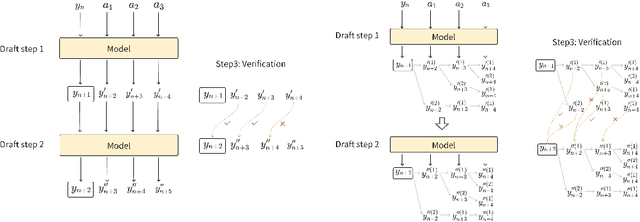
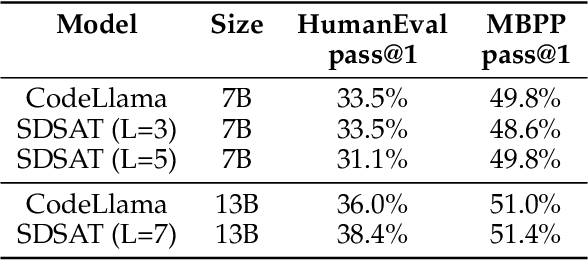
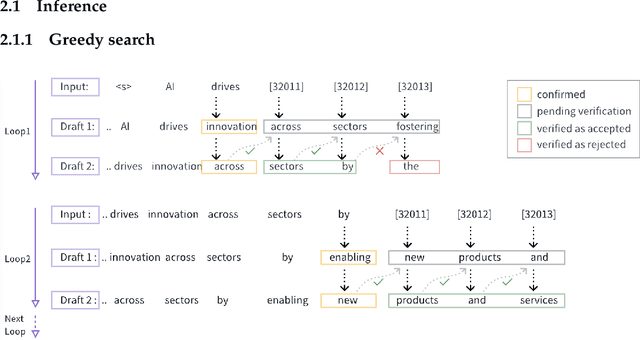
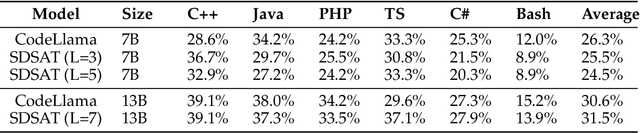
We propose an acceleration scheme for large language models (LLMs) through Speculative Decoding with Semantic Adaptive Tokens (SDSAT). The primary objective of this design is to enhance the LLM model's ability to generate draft tokens more accurately without compromising the model's accuracy. The core strategies involve: 1) Fine-tune the model by incorporating semantic adaptive tokens that possess flexible decoding capabilities without changing its structure, allowing them to generate high-quality draft tokens. 2) By employing a training method that does not affect the standard tokens, the model can acquire parallel decoding abilities atop its original framework with minimal training overhead. 3) We have designed the "two-step-draft-then-verify" generation strategies using both greedy search and nucleus sampling. Experiments conducted on the CodeLlama-13B and 7B models have yielded speed increases of over 3.5X and 3.0X, respectively. Please refer to https://github.com/hasuoshenyun/SDSAT.