 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiNeR: a Large Realistic Dataset for Evaluating Compositional Generalization
Jun 07, 2024Most of the existing compositional generalization datasets are synthetically-generated, resulting in a lack of natural language variation. While there have been recent attempts to introduce non-synthetic datasets for compositional generalization, they suffer from either limited data scale or a lack of diversity in the forms of combinations. To better investigate compositional generalization with more linguistic phenomena and compositional diversity, we propose the DIsh NamE Recognition (DiNeR) task and create a large realistic Chinese dataset. Given a recipe instruction, models are required to recognize the dish name composed of diverse combinations of food, actions, and flavors. Our dataset consists of 3,811 dishes and 228,114 recipes, and involves plenty of linguistic phenomena such as anaphora, omission and ambiguity. We provide two strong baselines based on T5 and large language models (LLMs). This work contributes a challenging task, baseline methods to tackle the task, and insights into compositional generalization in the context of dish name recognition. Code and data are available at https://github.com/Jumpy-pku/DiNeR.
Counterfactual Recipe Generation: Exploring Compositional Generalization in a Realistic Scenario
Oct 20, 2022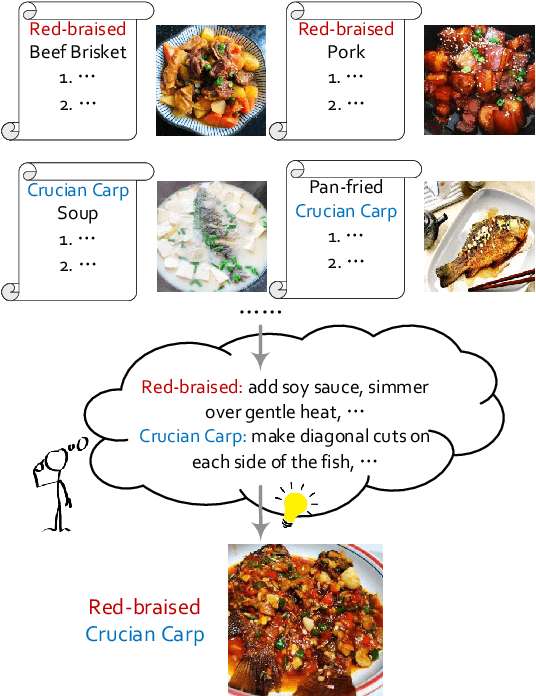


People can acquire knowledge in an unsupervised manner by reading, and compose the knowledge to make novel combinations. In this paper, we investigate whether pretrained language models can perform compositional generalization in a realistic setting: recipe generation. We design the counterfactual recipe generation task, which asks models to modify a base recipe according to the change of an ingredient. This task requires compositional generalization at two levels: the surface level of incorporating the new ingredient into the base recipe, and the deeper level of adjusting actions related to the changing ingredient. We collect a large-scale recipe dataset in Chinese for models to learn culinary knowledge, and a subset of action-level fine-grained annotations for evaluation. We finetune pretrained language models on the recipe corpus, and use unsupervised counterfactual generation methods to generate modified recipes. Results show that existing models have difficulties in modifying the ingredients while preserving the original text style, and often miss actions that need to be adjusted. Although pretrained language models can generate fluent recipe texts, they fail to truly learn and use the culinary knowledge in a compositional way. Code and data are available at https://github.com/xxxiaol/counterfactual-recipe-generation.