 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Use of Mutual Coherence to Prove $\ell^1/\ell^0$-Equivalence in Classification Problems
Jan 09, 2019

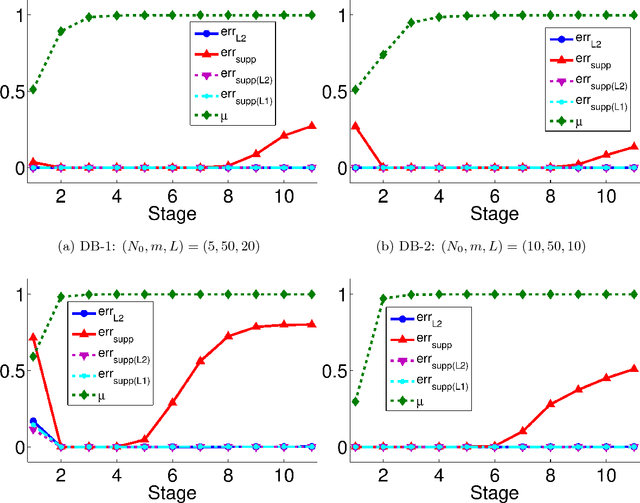
We consider the decomposition of a signal over an overcomplete set of vectors. Minimization of the $\ell^1$-norm of the coefficient vector can often retrieve the sparsest solution (so-called "$\ell^1/\ell^0$-equivalence"), a generally NP-hard task, and this fact has powered the field of compressed sensing. Wright et al.'s sparse representation-based classification (SRC) applies this relationship to machine learning, wherein the signal to be decomposed represents the test sample and columns of the dictionary are training samples. We investigate the relationships between $\ell^1$-minimization, sparsity, and classification accuracy in SRC. After proving that the tractable, deterministic approach to verifying $\ell^1/\ell^0$-equivalence fundamentally conflicts with the high coherence between same-class training samples, we demonstrate that $\ell^1$-minimization can still recover the sparsest solution when the classes are well-separated. Further, using a nonlinear transform so that sparse recovery conditions may be satisfied, we demonstrate that approximate (not strict) equivalence is key to the success of SRC.
Improving Sparse Representation-Based Classification Using Local Principal Component Analysis
Jun 02, 2018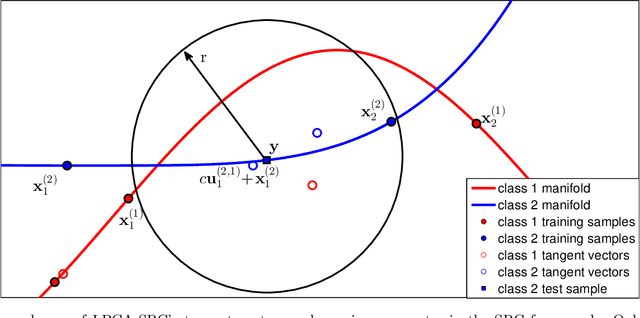



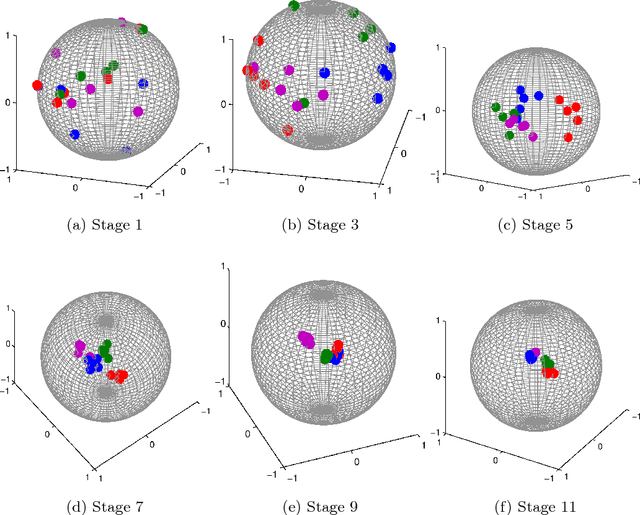
Sparse representation-based classification (SRC), proposed by Wright et al., seeks the sparsest decomposition of a test sample over the dictionary of training samples, with classification to the most-contributing class. Because it assumes test samples can be written as linear combinations of their same-class training samples, the success of SRC depends on the size and representativeness of the training set. Our proposed classification algorithm enlarges the training set by using local principal component analysis to approximate the basis vectors of the tangent hyperplane of the class manifold at each training sample. The dictionary in SRC is replaced by a local dictionary that adapts to the test sample and includes training samples and their corresponding tangent basis vectors. We use a synthetic data set and three face databases to demonstrate that this method can achieve higher classification accuracy than SRC in cases of sparse sampling, nonlinear class manifolds, and stringent dimension reduction.