 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Knowledge Discovery with General Line Coordinates
May 28, 2023Understanding black-box Machine Learning methods on multidimensional data is a key challenge in Machine Learning. While many powerful Machine Learning methods already exist, these methods are often unexplainable or perform poorly on complex data. This paper proposes visual knowledge discovery approaches based on several forms of lossless General Line Coordinates. These are an expansion of the previously introduced General Line Coordinates Linear and Dynamic Scaffolding Coordinates to produce, explain, and visualize non-linear classifiers with explanation rules. To ensure these non-linear models and rules are accurate, General Line Coordinates Linear also developed new interactive visual knowledge discovery algorithms for finding worst-case validation splits. These expansions are General Line Coordinates non-linear, interactive rules linear, hyperblock rules linear, and worst-case linear. Experiments across multiple benchmark datasets show that this visual knowledge discovery method can compete with other visual and computational Machine Learning algorithms while improving both interpretability and accuracy in linear and non-linear classifications. Major benefits from these expansions consist of the ability to build accurate and highly interpretable models and rules from hyperblocks, the ability to analyze interpretability weaknesses in a model, and the input of expert knowledge through interactive and human-guided visual knowledge discovery methods.
Interpretable Machine Learning for Self-Service High-Risk Decision-Making
May 09, 2022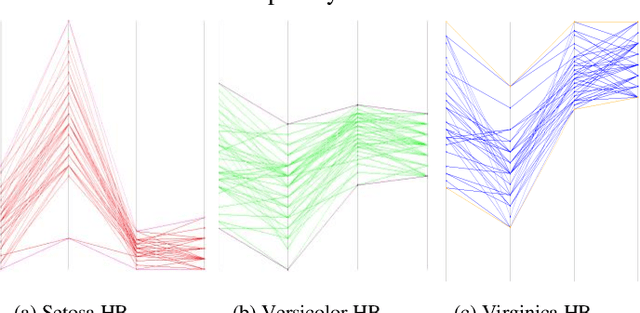
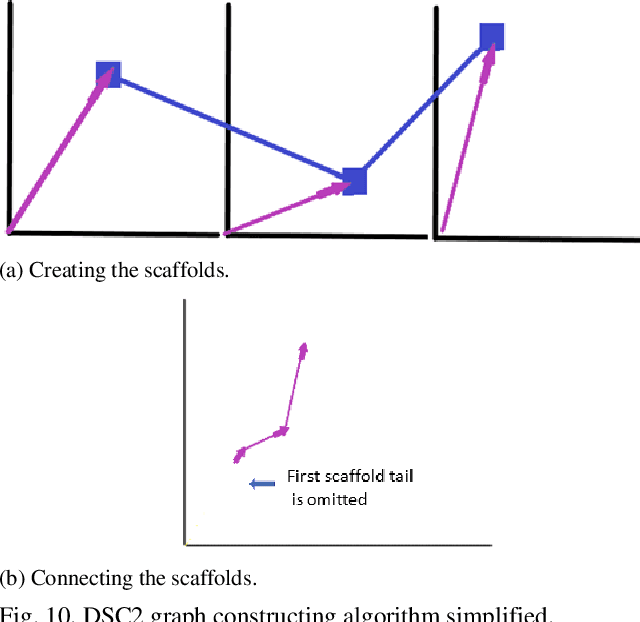
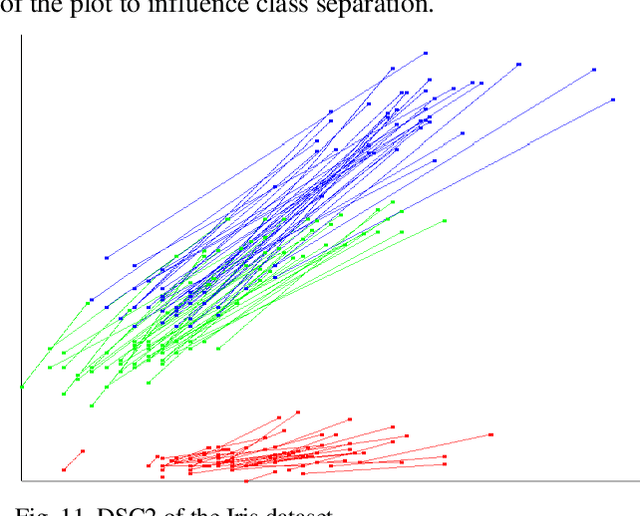
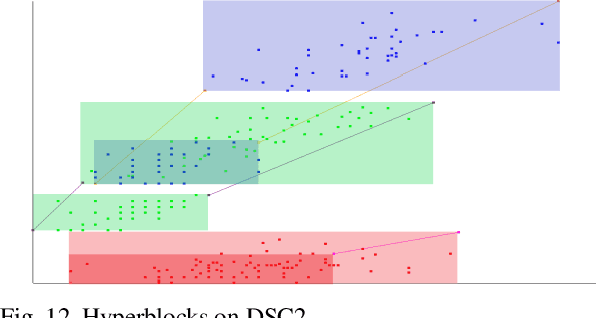
This paper contributes to interpretable machine learning via visual knowledge discovery in general line coordinates (GLC). The concepts of hyperblocks as interpretable dataset units and general line coordinates are combined to create a visual self-service machine learning model. The DSC1 and DSC2 lossless multidimensional coordinate systems are proposed. DSC1 and DSC2 can map multiple dataset attributes to a single two-dimensional (X, Y) Cartesian plane using a graph construction algorithm. The hyperblock analysis was used to determine visually appealing dataset attribute orders and to reduce line occlusion. It is shown that hyperblocks can generalize decision tree rules and a series of DSC1 or DSC2 plots can visualize a decision tree. The DSC1 and DSC2 plots were tested on benchmark datasets from the UCI ML repository. They allowed for visual classification of data. Additionally, areas of hyperblock impurity were discovered and used to establish dataset splits that highlight the upper estimate of worst-case model accuracy to guide model selection for high-risk decision-making. Major benefits of DSC1 and DSC2 is their highly interpretable nature. They allow domain experts to control or establish new machine learning models through visual pattern discovery.