 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScience Checker: Extractive-Boolean Question Answering For Scientific Fact Checking
Apr 29, 2022
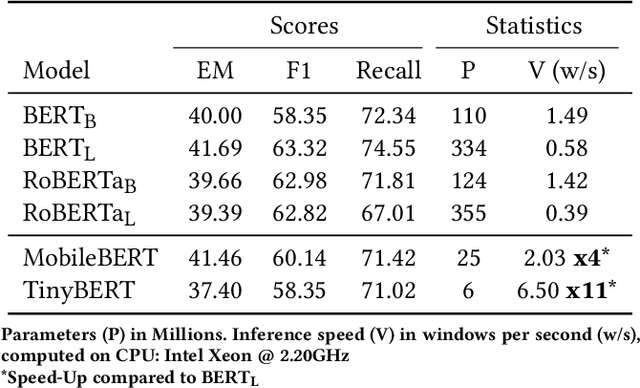
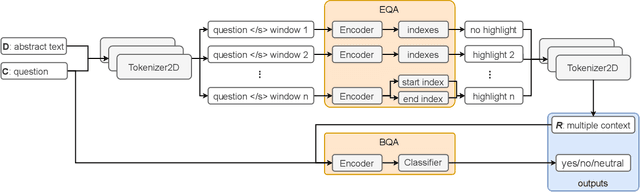
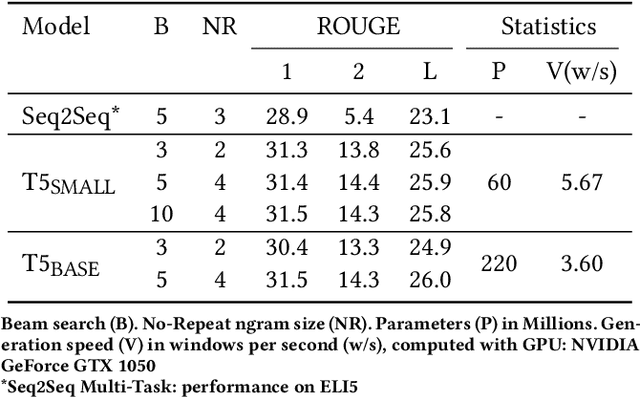
With the explosive growth of scientific publications, making the synthesis of scientific knowledge and fact checking becomes an increasingly complex task. In this paper, we propose a multi-task approach for verifying the scientific questions based on a joint reasoning from facts and evidence in research articles. We propose an intelligent combination of (1) an automatic information summarization and (2) a Boolean Question Answering which allows to generate an answer to a scientific question from only extracts obtained after summarization. Thus on a given topic, our proposed approach conducts structured content modeling based on paper abstracts to answer a scientific question while highlighting texts from paper that discuss the topic. We based our final system on an end-to-end Extractive Question Answering (EQA) combined with a three outputs classification model to perform in-depth semantic understanding of a question to illustrate the aggregation of multiple responses. With our light and fast proposed architecture, we achieved an average error rate of 4% and a F1-score of 95.6%. Our results are supported via experiments with two QA models (BERT, RoBERTa) over 3 Million Open Access (OA) articles in the medical and health domains on Europe PMC.
* 8 pages, 4 figures
BagBERT: BERT-based bagging-stacking for multi-topic classification
Nov 10, 2021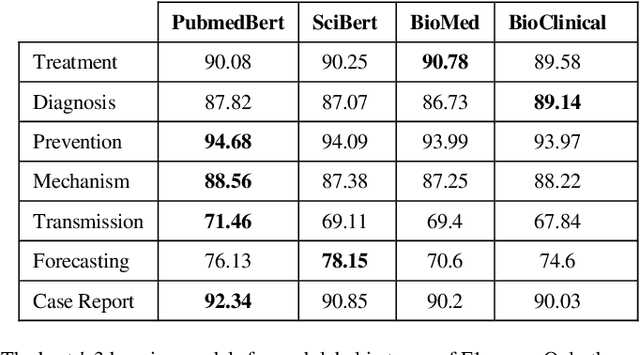
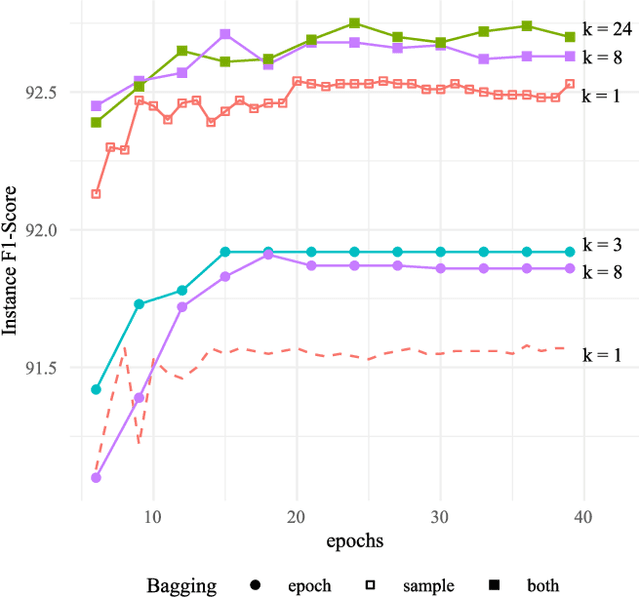
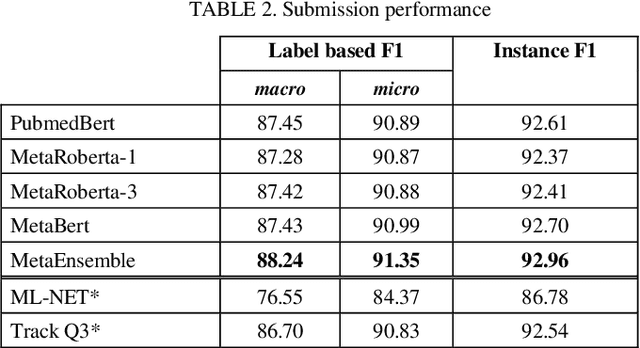
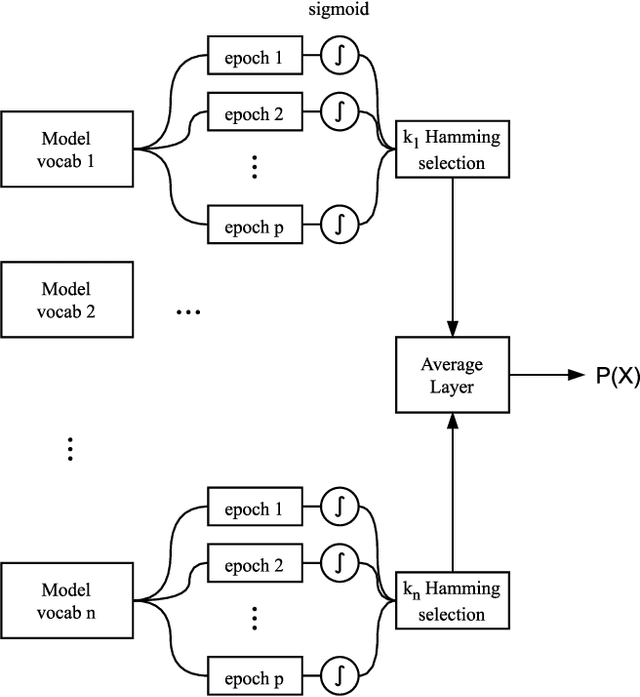
This paper describes our submission on the COVID-19 literature annotation task at Biocreative VII. We proposed an approach that exploits the knowledge of the globally non-optimal weights, usually rejected, to build a rich representation of each label. Our proposed approach consists of two stages: (1) A bagging of various initializations of the training data that features weakly trained weights, (2) A stacking of heterogeneous vocabulary models based on BERT and RoBERTa Embeddings. The aggregation of these weak insights performs better than a classical globally efficient model. The purpose is the distillation of the richness of knowledge to a simpler and lighter model. Our system obtains an Instance-based F1 of 92.96 and a Label-based micro-F1 of 91.35.